



Oct 3, 2022
What Is Attribute-Based Access Control (ABAC) and How Does It Benefit Your Enterprise?
Read More

Recently there has been a lot of debate in the data governance circles about the pros and cons of various approaches to implementing data access controls. We have also written on this topic to educate the market, as we do not believe that taking an extreme position is in the best interest of our customers. In this blog, we outline some of the most common scenarios that lead companies to create and enforce access control policies and outline a set of recommendations that would be helpful to companies navigating this landscape.
The most common use case for provisioning data access is when a company hires new employees. These employees require access to specific enterprise data in order to do their jobs. In the example below, Jane has been hired by ACME Corporation as a financial analyst. In this role, Jane would typically need to access data in the company’s general ledger, payables, and financials applications. The access to data is clearly based on the employee’s role — in Jane’s case, her role as a financial analyst for ACME Corp. The aspects of Jane’s job that identify her as an employee of the ACME — her title, her status as a full-time employee, the organization of which she is a part, and the location where she is based are all associated with Jane’s role in the company.
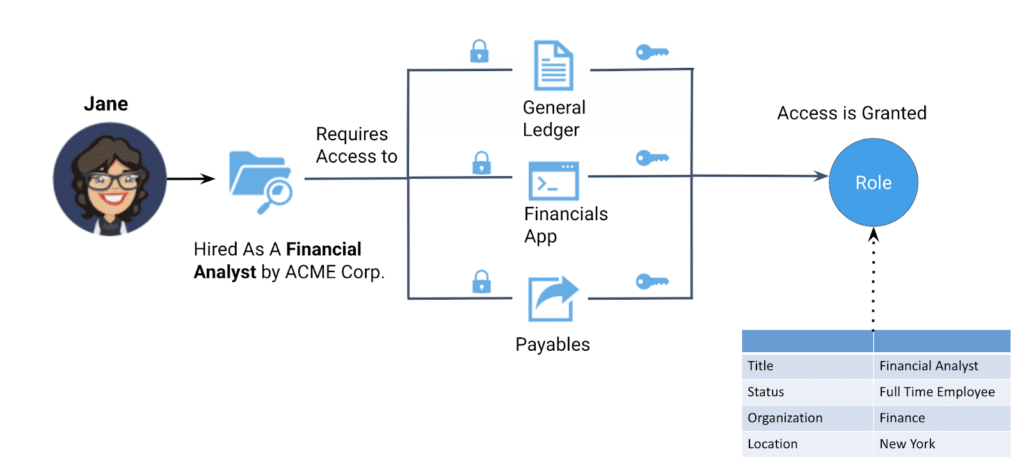
When ACME Corp decides to hire another employee in the position of a financial analyst, the IT administrator simply needs to assign the new employee to the same role (i.e., Financial Analyst) and they will have access to the same data sources that Jane does. In this way, the business organizational structure and human resources processes correspond directly, and predictably, to the required data access. We explained how users can be assigned to roles that give them permission to perform specific operations on data in a previous blog.
So what happens in Jane’s career, and what does that mean for her data access entitlements? Let’s take this example a little further. Jane is now being promoted to the position of Lead Data Scientist at ACME. In addition to the data sources to which she previously had access, she now needs access to demographic data, ACME’s transactional data, and customer medical data in order to build machine learning models. To qualify for this level of access, Jane is asked to complete a course in the ethical use of data. In this scenario, some aspects of Jane’s role have changed, such as her title and organization. But these attributes are still tied to her new role. To provision the correct access, the administrator (or HR system) simply needs to reassign her to the Lead Data Scientist role in the analytics organization, and her entitlement to the additional data sources will be automatically granted. In this way, the association of organizational role predictably drives data entitlements.
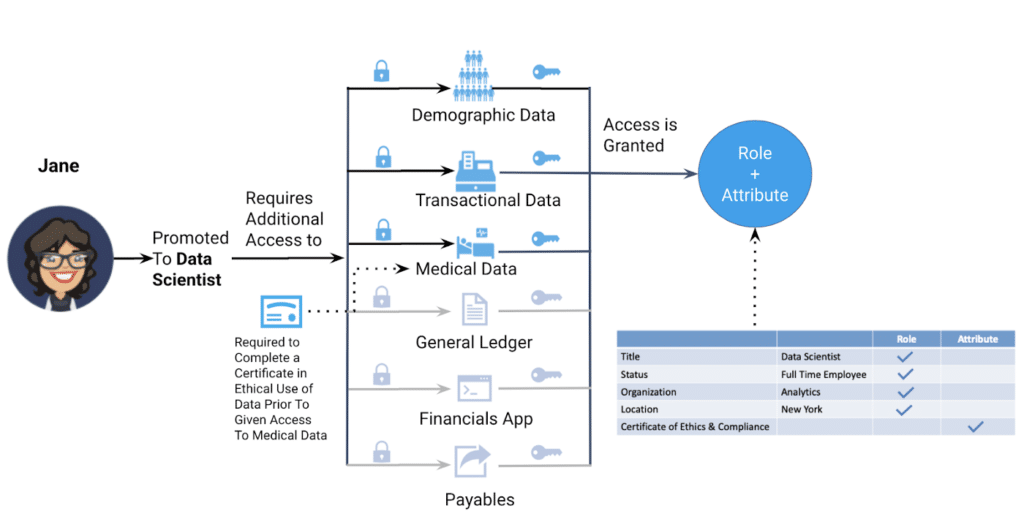
However, this role-based access must be modified a bit. Employees in the Lead Data Scientist role also need to complete the ethics course before being allowed access to certain sensitive data. Jane’s role entitles her to many data resources, but some must be blocked until she has successfully completed the ethics program. This attribute is combined with her organizational role to determine whether she can access the medical data. The data access pattern exactly matches the real-world attribute and role assigned to Jane.
The majority of access controls in the real world are role-based — tied to the job role of the individual. There are also critical instances where an access control policy needs to be attribute-based such as Jane’s certificate of ethics and compliance in the example above. Tools like Apache Ranger and Privacera are built to make both role and attribute-based policies work as Compliance and Legal teams need them to, with minimal complexity and high repeatability.
A lot of confusion in the market is caused by a lack of understanding about how access control policies are constructed and administered. A platform like Privacera that has been specifically built for high-performance access control will likely result in superior performance — and lower operating costs — versus a tool that has been retrofitted from business intelligence or reporting use case and re-purposed for data governance applications.
It seems obvious that even the best tool will not produce the desired results when it is not used according to its design principle. This cannot be more true for access control platforms. For example, if an administrator chooses to build a new policy for each and every user in the company, rather than creating organizational roles and assigning users to those roles, it will work, but it will result in a large number of policies and long-term challenges in maintenance and transparency. This well-intentioned administrator would be using the platform in a suboptimal way and putting enterprise data and customers at risk. Privacera’s advice to companies interested in providing secure access to their data consumers is to thoroughly evaluate the performance of the solution they plan to use, the experience and origins of vendors and experts, and investigate whether the underlying architecture requires extensive manual maintenance, such as look-up tables, SQL views, and invisible assumptions, as these will lead to scalability issues and require re-implementation.

Schedule a demo with us today to see first-hand how the Privacera Access Manager provides data access governance with centralized management of authorization policies and auditing.
Author