



Apr 18, 2022
Our Tribute to Apache Ranger, by Extending its Greatness to the Cloud
Read More

“The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.”
– Stephen Hawking
In the hyper-competitive space of enterprise software, it is not uncommon to come across benchmark studies that show the advantages of one product over another based on criteria such as performance or scalability. However, it is critical for these benchmarks to be objective in order to be useful for the readers. Recently, we came across a widely distributed GigaOm report sponsored by Immuta that benchmarked the results of implementing access control policies for various scenarios via Apache Ranger versus Immuta’s offering. The challenge with these types of studies for vendors and publishers is that it hinges on your criteria being repeatable and also representative of the correct or proper usage of the product(s) tested – usually requiring expert users of the products in question. While we do not know whether Immuta made use of experts for both products, this benchmark appears to extensively misuse Apache Ranger which, in turn, creates a misleading view of the relative strengths of this product. Our assertion is the study suffers from the following shortcomings:
For those less familiar with Apache Ranger, it is one of the leading open-source projects used by Fortune 500 companies for data governance. With more than 15 major and minor software releases under its belt – as well as contributions from Microsoft, Accenture, eBay, ING, and Huawei – Apache Ranger has become a leading security and authorization component adopted by the market leaders, such as Amazon EMR, Google Cloud Dataproc, and more, to securely manage their data ecosystems.
The GigaOm report appears to misuse Ranger which results in massive proliferation of the number of policies, and then inflated ownership costs based on that error.
If a driver only drives the car in first gear and complains of not moving faster doesn’t mean that the car is not capable of running at higher speeds; it simply means that the driver is not using the full power of the engine by not shifting to higher gears. The same principle applies to software products.

The report fails the first rule of doing product comparisons – which is to use the product (Ranger) as documented. For example, those familiar with Ranger – or those who have worked in information security – know that it is a risky and labor-intensive anti-pattern to build a new access control policy for every user that is added to the system. A more reasonable method would be to associate additional users to the existing policy. This simple and intuitive approach can significantly reduce the number of policies. However, the GigaOm benchmark ignored this capability, which resulted in a favorable position for Immuta. Just like it doesn’t make sense to create a policy for every user who is added to the environment, it is illogical to recreate policies for every derived datasets. In fact, the best practice is to write a policy that can be used consistently across datasets. One of the ways the benchmark results would have looked drastically different is if the report simply added the newly created datasets to existing policies.
It’s also worth noting that the researchers failed to mention Ranger’s row-level filtering that can significantly reduce the number of policies. Enterprise customers typically use an approach like lookup tables to create a single policy to cover a large number of use cases. For example, with the use of the lookup table user_store_access, the following filter expression can be used:
store_id in (select store_id from user_store_access u where u.user = current_user())
This is a practice applied by most customers and is easily found in Apache Ranger’s documentation. The filter can be extended to support groups, roles, and user attributes. Again, the researchers chose to use this simpler approach when evaluating the sponsor’s product, but not when using Apache Ranger.
The researchers also chose to use a count of “policies” as a metric. The problem is this metric ignores all the intermediate steps that are required to build a policy by calling them something else, such as rules, and only counting the application of rules as a policy. So, in spite of the fact that conditions, tags, rules, and other objects must be created and manually managed, the researchers left these tasks out of their policy count. Now, consider the effort of manually tagging thousands of columns…is it really less labor to manage a hundred objects if the vendor just stops calling them “policies”? Without any details to reproduce the benchmark, is the reader expected to simply accept the report’s validation of the sponsor’s product? Anyone who reads the report has no way to validate the stated number of Immuta policies, not to mention the possible complexity underneath the shiny cover.
This, once again, raises the question mark on the credibility of the report, as it uses obviously false and incorrect metrics to try and create a better performance rating for Immuta. For instance, the report states that Apache Ranger requires 55 steps to create a policy to restrict access to PII data. This is factually incorrect. If GigaOm researchers used the denyAllElse flag in Ranger, this task would only take 2 policies versus Immuta to complete the same task.
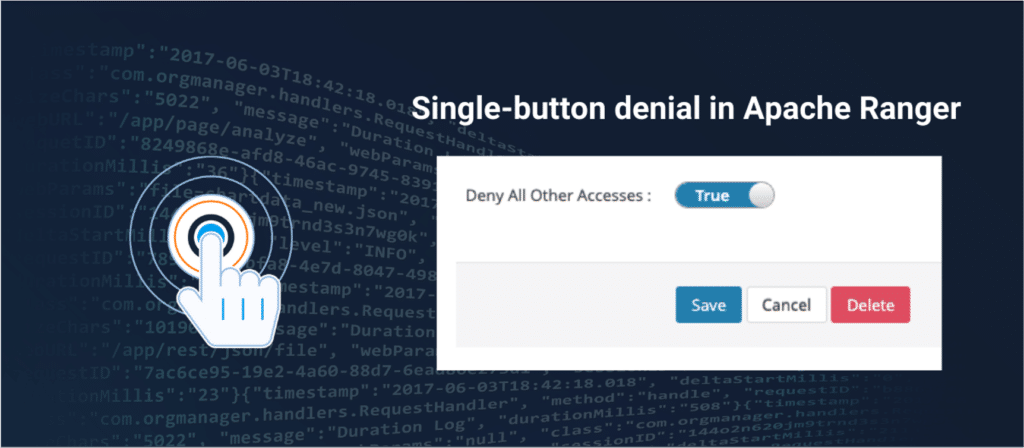
It is unfortunate that the GigaOm researchers failed to consult experts within the Apache Ranger community and/or Privacera regarding this report. When one of our Apache Ranger experts – Madhan Neethiraj, a PMC and founding member who played a major role in the core design of Ranger policy model and policy engine – reviewed the report, his assertion was that the number of policies required to perform the outlined tasks can be significantly reduced. The result is the reduction in the total number of policies from GigaOm’s inflated 603 to just 28 through the proper usage of Apache Ranger, a stunning 95% reduction with obvious cost implications. Further, the researchers did not take into account software subscription and scaling the hundreds and thousands of objects. If the report completely missed the mark on the number of policies then the question readers must ask is what else the report gets wrong in terms of methodology, rigor and objectivity?
The misuse of Ranger’s functionality, combined with selective manipulation of terminology, creates a snowball effect in the report. This is because inaccurate performance metrics were built on top of each other, creating an illusion of reduced projected time and labor cost for the sponsor’s product. It goes without saying that if you get the first part of a multi-step problem wrong, then the answer will never be correct.
Another important fact that was omitted was Immuta’s proprietary software could cost hundreds of thousands dollars a year in licensing; whereas, Apache Ranger is an open-source software that is free for consumption. If this is factored in, it would completely eliminate the fabricated financial advantage of the sponsor’s product.
With the inaccuracies in GigaOm’s report revealed, the benchmark fails to offer a valid or accurate representation for companies interested in implementing an access governance solution. Sophisticated businesses use a combination of scalability, performance, usability, availability and maintenance — commonly referred as enterprise-readiness criteria — to select IT solutions. It is overly simplistic to think the steps required to create and modify policies (although misguided) would be the sole criteria for such a selection. The report intentionally evades criteria where architectural choices (eg. data virtualization technology versus massively scaled-out systems like Apache Ranger) can lead to scalability and performance issues in a real-world environment when enabling data masking and other security features, and performing complex queries. Rather than depending on fuzzy math to present “conservative estimates” of policy burden cost, below are results of an actual POC that a Fortune 100 customer obtained:
Here, you can clearly see the performance degradation as the volume of data and the complexity of data security tasks increase. The situation only gets worse as you onboard more databases and systems in the virtualized solution, because now more data will go through the single layer and eventually it will choke the performance of the entire system. Not to mention, the significant administrative effort required to synchronize the metadata and configure the policies for every database. And let’s not forget the cost and risk of vendor lock-in. Proprietary and closed-source solutions are not only difficult to customize, they leave customers at the mercy of the vendor to add new features or support new data source systems.
The report attempts to label Apache Ranger as a legacy solution that is only relevant for Hadoop environments. The real truth is Ranger is at the core of almost all modern data management and analysis tools available today: EMR (Hadoop), Databricks (Apache Spark), Starburst (Trino), Confluent (Apache Kafka), Glue (Apache Hive Metastore), DataProc (Hadoop), HDInsight (Hadoop) and many more. Accepted across industries as a robust access control platform, Apache Ranger is currently in use by 1000s of enterprises and is natively integrated by all major cloud vendors like AWS, GCP and Azure. It is also the security platform of choice for pure-play data virtualization vendors like Dremio and Starburst. Due to its robustness and proven scalability, Privacera has chosen Apache Ranger as its underlying engine for access control and it has advanced its capability with many out-of-the-box features, such as simplified policy authoring, data discovery and encryption, and native integrations with all modern data platforms like Databricks, Snowflake, BigQuery, Azure Synapse, Redshift and more. Privacera has evolved and optimized its technology for the data environment and will continue to leverage the power Apache Ranger brings to help future proof data access governance for our customers who, without exception, operate in multi-cloud, hybrid data estates to become data driven organizations.
Companies that are currently evaluating access governance technology must weigh the validity of GigaOm’s report against the tried-and-true success of Apache Ranger and its immense open-source community backing to come to a more accurate conclusion.
Learn about the correct usage and cost savings of Apache Ranger and how to seamlessly migrate data and associated Ranger policies from on-prem to cloud by contacting us today or by visiting www.privacera.com.
Author