




Aug 28, 2024
Activating Data Security Posture Management
Read More

As organizations embrace the transformative potential of Generative AI (GenAI) and machine learning, vector databases and embeddings have become critical components of the data infrastructure. These technologies enable efficient storage, retrieval, and analysis of unstructured data, powering applications like image recognition, recommendation systems, natural language processing (NLP), and enterprise search engines. However, with great power comes great responsibility -securing vector databases and embeddings is crucial to safeguarding sensitive data and ensuring compliance with data protection regulations, such as GDPR, CCPA, and others.
In this blog, we’ll explore what vector databases and embeddings are, the process of creating embeddings, and the best practices to secure these technologies. We’ll conclude with how Privacera’s PAIG (Privacera AI Governance) can help you enhance security and governance for vector databases and embeddings.
What Are Vector Databases? Vector databases are specialized data storage systems designed to handle high-dimensional vector data. Unlike traditional databases that store structured data in rows and columns, vector databases manage unstructured data such as images, audio, and text, represented as vectors. These vectors, which are multi-dimensional, encapsulate the essential features of the data and position related data in close proximity, making it easier to search and analyze using similarity measures.
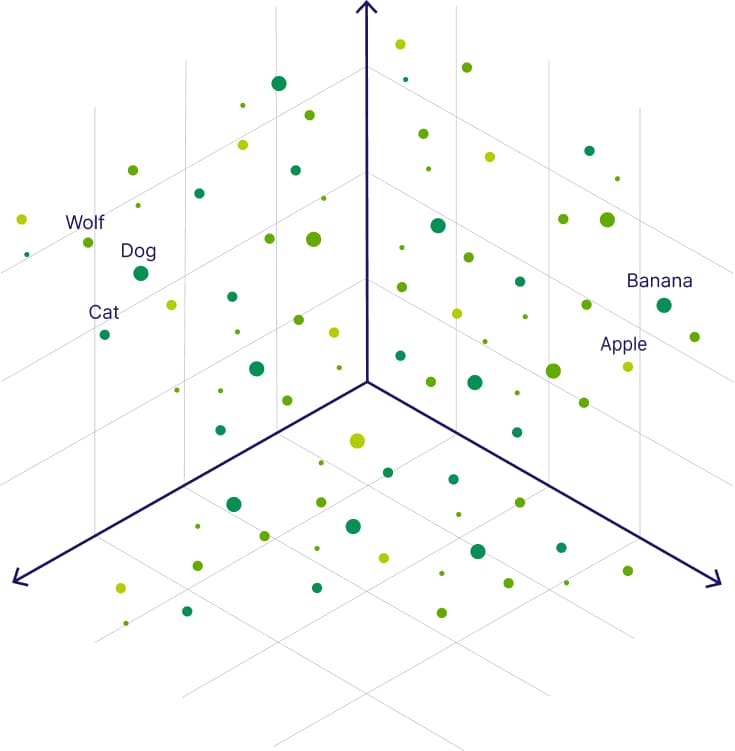
What Are Embeddings? Embeddings are dense vector representations of data. For instance, in NLP, embeddings transform words or sentences into fixed-length numerical vectors that capture semantic meaning. Popular embedding techniques include Word2Vec, GloVe, and transformer-based models like BERT. These embeddings enable efficient similarity comparisons and form the backbone of many AI applications.
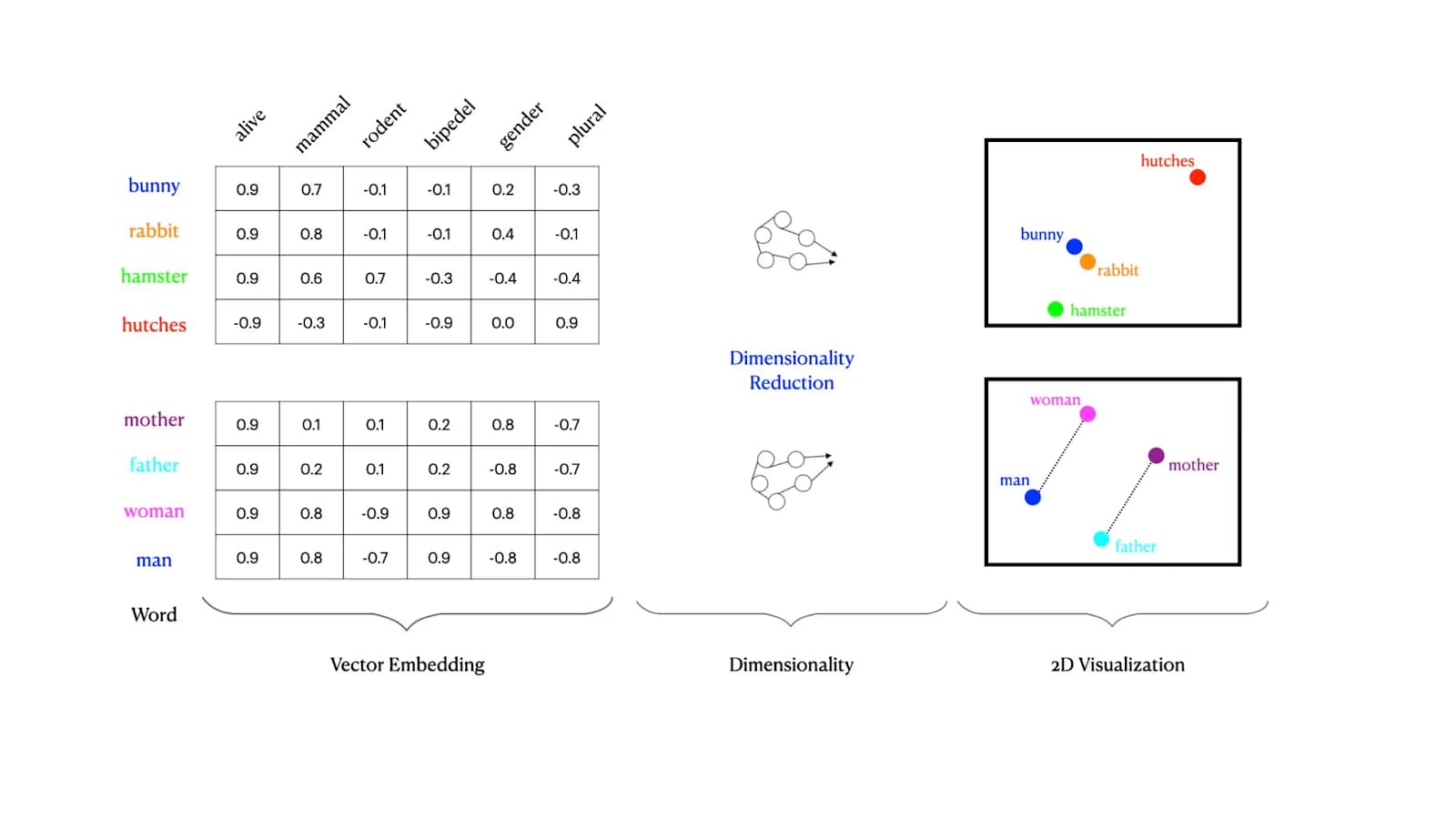
How Are Embeddings Created? The process of creating embeddings typically involves the following steps:
Notably, open-source frameworks like LangChain have been designed to simplify the development of applications using vector databases and embeddings, offering developers powerful tools to streamline integration and functionality. While these steps enable the creation of powerful AI-driven applications, they also introduce security risks that must be addressed.
Securing vector databases and embeddings requires a layered approach. Below are seven key strategies organizations should follow. While a range of techniques can be employed to secure vector databases and embeddings, this blog will delve deeper into two essential practices: Access Control and Anonymization and Pseudonymization.
By employing these strategies, organizations can safeguard vector databases and ensure embeddings are secure and compliant.
Now, let’s delve deeper into two critical practices for securing vector databases and embeddings: Access Control and Anonymization and Pseudonymization. In future blogs, we will cover the other 5 best practices.
Access control is critical to safeguarding vector databases. Traditional access control systems were built for relatively static environments, but GenAI applications demand a more dynamic approach. To effectively implement access control, organizations should take a multi-layered and prescriptive approach:
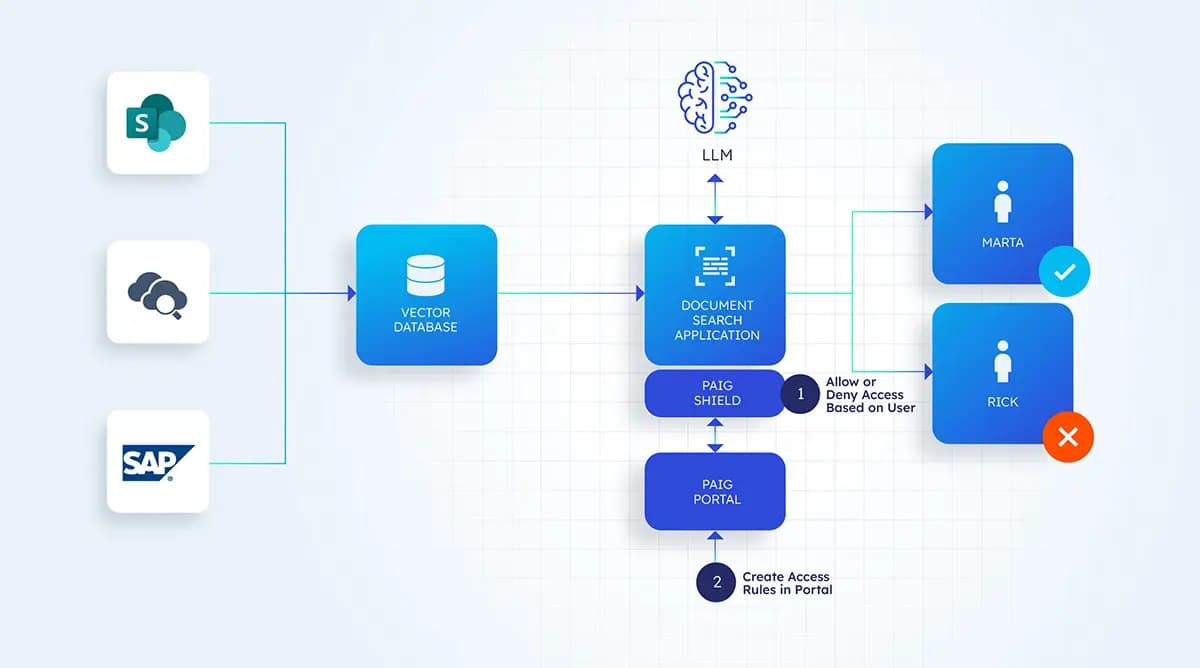
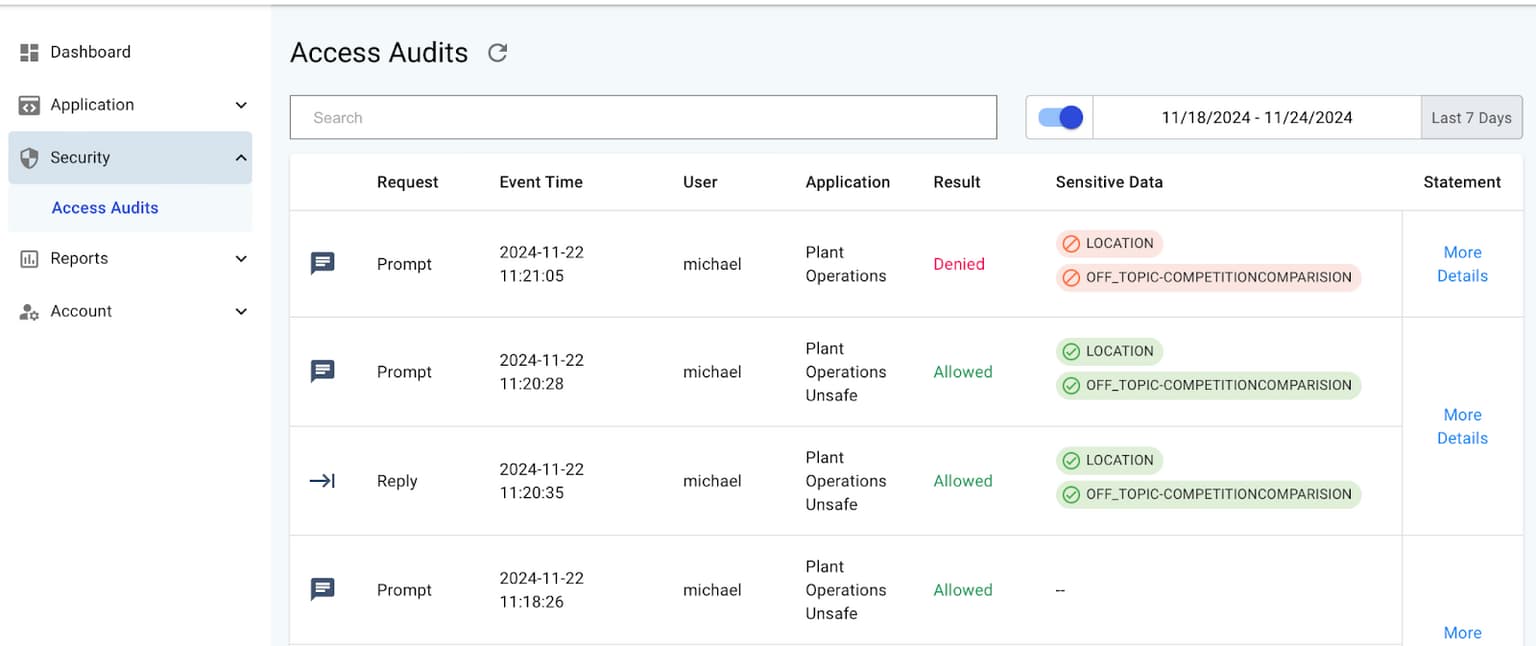
For a deeper understanding, consider reading this blog on the evolution of access control and its implications for GenAI applications and this blog on challenges with access control in RAG systems.
Watch this short demo to see how Privacera AI Governance (PAIG) enforces secure data access in a GenAI-powered chat application. The demo compares a secured and unsecured version of the app, highlighting how PAIG applies role-based access controls and metadata-driven filtering to prevent accidental data leaks.
Anonymizing data before creating embeddings reduces the risk of exposing sensitive information. Techniques such as generalization (replacing specific data points with broader categories) and suppression (removing sensitive fields) are effective. Pseudonymization—replacing identifiable data with tokens—balances usability with privacy. For added security, organizations can combine these methods with differential privacy techniques to further obfuscate patterns, ensuring embeddings do not inadvertently reveal personal data.
To implement these techniques effectively, open-source tools like Google’s Differential Privacy Library or OpenDP can be integrated into the embedding pipeline. These libraries provide algorithms that introduce statistical noise to datasets, preserving privacy without compromising the utility of embeddings. Additionally, preprocessing frameworks like Apache NiFi can be utilized to automate anonymization workflows, ensuring consistent application of policies across large datasets.
As we embrace the potential of GenAI, traditional authorization and access control models are proving insufficient to address the unique challenges posed by dynamic AI interactions, complex data use cases, and unpredictable model behavior. The industry must rethink access governance to ensure that GenAI systems are secure, compliant, and trustworthy.
Organizations building GenAI solutions must prioritize adaptive, contextual access control mechanisms that go beyond static permissions and embrace the dynamic, evolving nature of AI models. In doing so, we can unlock the full potential of Generative AI while safeguarding the data and users it impacts. Privacera AI Governance (PAIG) is the industry’s first comprehensive security, safety and governance solution for GenAI applications. PAIG operates independently from your choices of models, libraries and RAG approaches to truly provide a holistic security and observability platform. You can start your journey with PAIG today by scheduling a demo here or you can get started on the open source version of PAIG.
