



May 3, 2021
Discover, Classify and Catalog Sensitive Data on AWS with Privacera
Watch the Video

Deployment options for PrivaceraCloud and Privacera Platform
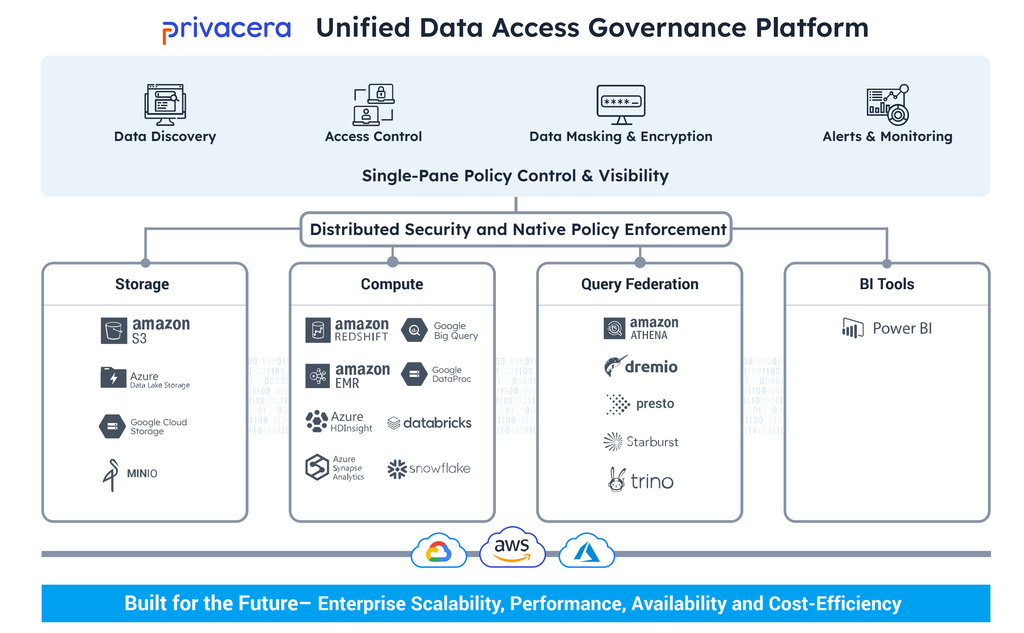
Privacera provides a data access governance platform to enable secure data sharing across hybrid environments and cloud services. It is based on Apache Ranger for comprehensive data security across on-premise data lakes. Privacera removes the dependence on multiple processes to provide fast, easy and secure data sharing that empowers teams to both make data widely available in the organization while fully complying with regulations. Learn more about these fundamental concepts below, including where you can run Privacera.
PrivaceraCloud is a Data Access Governance solution where the customer does not need to install, maintain, or update the software. Administrators can centrally define and manage fine-grained access control policies, and provide reports, dashboards, and alerts required for data audits compliance, audit, and governance purposes.
Who is PrivaceraCloud for? PrivaceraCloud can be used by administrators at companies that currently use major cloud-native services and data warehouses, including Databricks, Amazon EMR (Hive & Presto), Starburst, Snowflake, Azure Data Lake Storage (ADLS), Azure Synapse, Amazon Redshift, Amazon Athena, Amazon S3, and Postgres.
PrivaceraCloud Setup (applicable only for a data plane configuration) is an additional functionality of SaaS that allows seamless integration of Privacera data services within the customer’s data center, ensuring sensitive business data stays securely within their own infrastructure instead of being sent to Privacera for processing. By adopting this approach, customers can leverage PrivaceraCloud to create and manage policies and audit information while retaining full control over their data, which remains stored in their data center and is accessible solely within the enterprise network.
You can try PrivaceraCloud free for 30 days. Just fill out this quick form to get started.
Privacera’s Unified Data Security Platform provides the data governance tools you need to manage the entire data security lifecycle to identify and protect sensitive data, and simplify access management across your entire data estate.
The self-managed Privacera Platform runs on the customer’s infrastructure. The customer downloads Privacera software to install it on their on-premises hardware or customer’s cloud account.
See first-hand what unified data security and AI governance can do for you. Request your expert consultation today.
In an increasingly data-driven world, organizations must comply with laws and regulations applicable to data privacy, storage, and processing and extract valuable insights. Data governance comprises the people and processes that organizations adapt to manage data used to support business operations. This includes:
Data owners and stewards are responsible for determining what data to collect, store, and share in the organization to drive business value, while ensuring compliance with all the regulations.
IT manages the infrastructure, rather than owning the data it holds. This distinction is important, as one of the most common challenges faced by organizations today remains the lack of proper data ownership, resulting in IT owning the data by default and using ad-hoc criteria to grant data access. This creates continuous friction between the business and IT organizations, which leads to data silos, increased risk of breaches or unauthorized access, and compliance violations that could negatively impact brand image and shareholder value.
Without clearly defined data owners and stewards, organizations end up spending more time on data storage and processing and replicating the same work in multiple business units (a common complaint among users, such as data scientists and analysts, is that they spend more time looking for data than on analyzing it to find embedded insights). This leads to missed opportunities to share data, inconsistent data quality standards, and increased risk of compliance violations, as the data is scattered across the organization.
Access control is the set of rules or framework used to ensure only the intended users have permission to access data. For example, permission to access a resource such as data in a database or a table, and perform an operation like read, write, edit, or delete. There are two prevalent approaches to managing access:
Understanding basic access control is important to understanding Apache Ranger, the open source data access control framework that Privacera builds upon.
Apache Ranger is the leading open-source data access governance project for big data environments and is in use at hundreds of enterprises around the world. Privacera builds on Apache Ranger to fill the need to extend the data governance and security from Hadoop to the wider cloud data ecosystem. Privacera supports multiple cloud services—AWS, Microsoft Azure, Google Cloud, Databricks, Snowflake, and more—in addition to other enhancements that are critical to securing analytical workloads by enterprises.
Privacera has extended Apache Ranger with three different approaches to policy enforcement based on the data store and the type of access for the environment.
Enterprises can automatically control policy creation and updates based on user requests in accordance with their roles or attributes for data access. This process replaces the prior manual authoring of access control policies and managing entitlements through manual user intervention of the policy administrators. With Privacera, data administrators have the flexibility to define access policies at a database, table, column, object, or file level. As a result, data administrators can administer fine-grained access controls for on-premises data lakes, public cloud services, and third-party cloud-native services all within Privacera.
Data encryption and data masking are two methods of data protection. Encryption encodes the sensitive data into an unreadable form to protect from external threats. Masking desensitizes the data from unauthorized users while still being usable, such as in a non-production environment.
Privacera Encryption has extended Apache Ranger’s encryption capability beyond big data to cover cloud services. With Privacera Encryption, organizations can encrypt data at the table, column, row, field, or attribute level instead of the entire data. This granular level of encryption enables the data science and analytics teams to utilize more data to build models and extract insights to drive new business opportunities, leading to increased customer satisfaction and optimized business efficiency. After the data is encrypted, this data is transparently decrypted for authorized users or applications when they access the data. The user experience of accessing encrypted data on a disk or in the cloud is identical to accessing non-encrypted data.
Sensitive data, such as social security numbers, street addresses, credit card information, and more, require some level of protection or governance to comply with privacy regulations or the enterprise’s own internal data usage requirements. With the volume of data created every day (by transactional systems, the Internet of Things, social media, and more), determining what data qualifies as sensitive is a daunting task. Before the era of Big Data, it was possible to manually identify sensitive data flowing into enterprise systems and view sensitive data stored within data infrastructures. But with the sheer volume of data created and stored across numerous sources today, manual efforts are not enough. Enterprises must embrace automation to understand and secure sensitive data.
Privacera Data Discovery enhances the Ranger functionality, empowering enterprises to leverage automation and sophisticated techniques to understand the context of sensitive data and accurately classify it. With Privacera Data Discovery, organizations can identify sensitive information in structured and unstructured data. It can also mask sensitive data based on enterprise use cases. All sensitive data classifications sync with Privacera Access Manager, enabling fine-grained access control at the file, table, row, and column levels for various data sources.
Privacera partners with the industry’s leading technology providers to ensure enterprises have automated, consistent governance and compliance across their entire IT infrastructures.
Sometimes these are referred to as 3rd party applications, data source connectors, or cloud/platform integrations, depending on the use case. For example, PrivaceraCloud provides access controls to secure data in the following cloud-native services and data warehouses:
EMR (Hive, Spark, Trino)
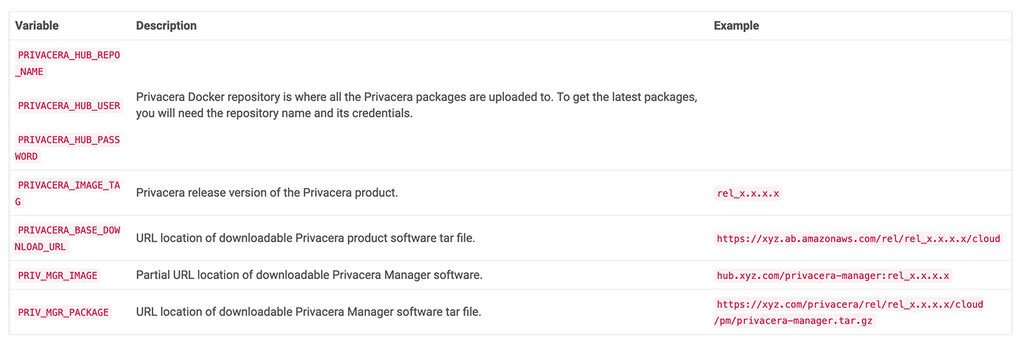
Use the following values to set your installation properties. If you require additional help, contact your Privacera technical support representative for assistance obtaining the correct values for the following variables.
Systems, requirements, regulations, and objectives vary across enterprises and regions. We’re here to support your data and AI governance, security, privacy, and compliance journey.
Current Privacera customers can click here for additional support.
If you’re not a Privacera customer, and have comments or questions, contact us here.
Author