



Aug 10, 2021
Immuta vs Apache Ranger: A Failed Benchmark
Read More
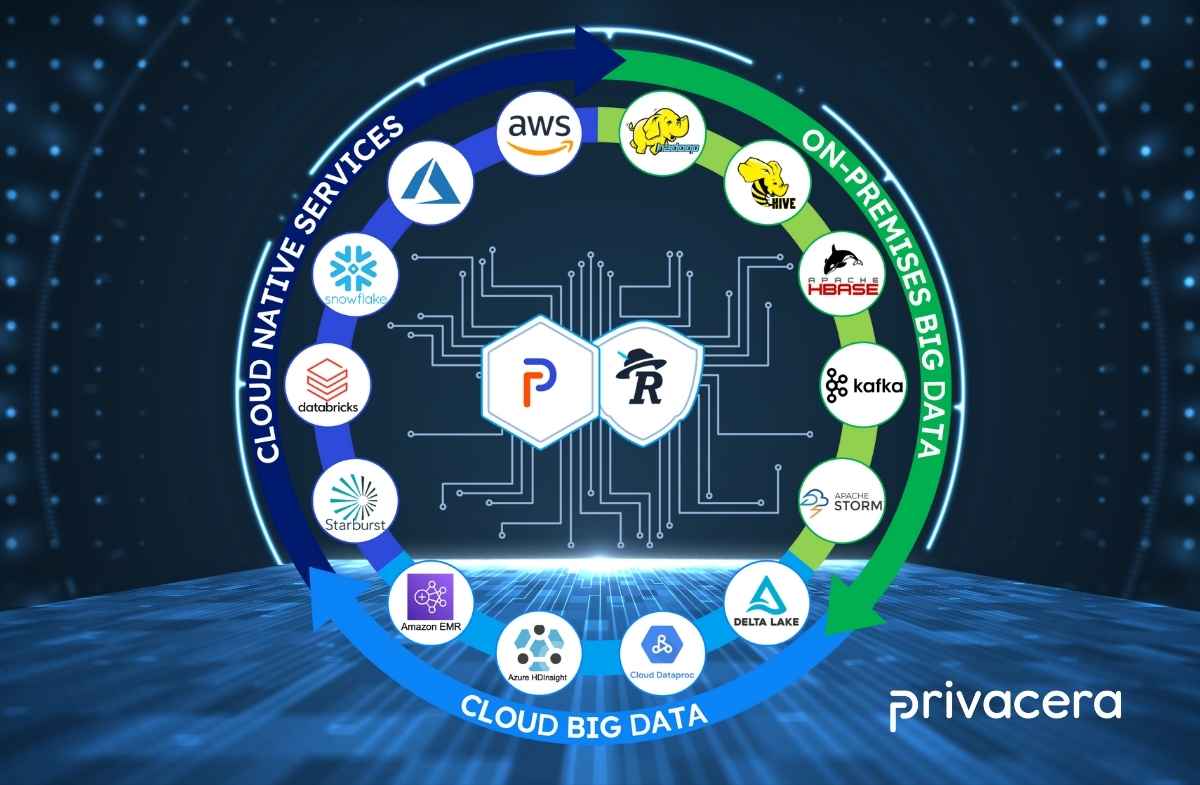
Imagine if Star Wars, The Lord of the Rings, and Harry Potter were only stories printed in books, Super Mario only available on the first-generation Nintendo console, and Louis Armstrong’s sounds only recorded on vinyl? For many great things in our lives, we find ways to better consume them and adapt them to fit the present time, whether in another format, on a new platform, or through a different distribution. These adaptations have happened many times in the tech world as well. While Apache Spark, Kafka, Presto started out as leading components for the on-premises Hadoop, they have been enhanced and extended to the cloud so enterprises can continue to reap the benefits of these great technologies in the new data environment. This was also the motivation behind the formation of Privacera that advanced Apache Ranger – a highly successful open-source project to centrally define and administer data access controls for the on-premises Hadoop data lakes – to the cloud. More importantly, now with all the “animals in the zoo” of Hadoop in the cloud as well as native cloud services such as Databricks and Snowflake, providing an enterprise-grade, proven data governance framework with comprehensive authorization, security, and audit capabilities needed is more critical than ever for modern enterprises.
Apache Ranger emerged on the big data scene to help enterprises secure their Hadoop platforms by using a centralized and open-source approach to authorize users’ access to various data repositories and compute engines. Ranger was the first to introduce the use of plugins purposely-built for access control. A plugin architecture featuring native integrations with the data sources provides a lightweight footprint that is easy to layer into complex storage and compute systems. Because the plugins are natively built for the source systems, they don’t introduce additional complexity, dependency, and overheads. Instead, they can swiftly authorize users and scale to thousands of users simultaneously accessing and querying data in production environments at a petabyte scale. For very high throughput services like Apache Kafka and Apache HBase, Ranger has a track record of performing thousands of authorizations per second.
Apache Ranger At A Glance
| Number of Releases (Major & Minor) | 17 |
| Number of Committers & Contributors | 71 |
| Formation of Apache Ranger as an incubator Project | 2014 |
| Recognition of Apache Ranger as a Top-Level Project (TLP) | 2017 |
| Lines of Code in the Latest Apache Ranger Release | 389,000 |
| Estimated Number of Companies Using Apache Ranger | 3000+ |
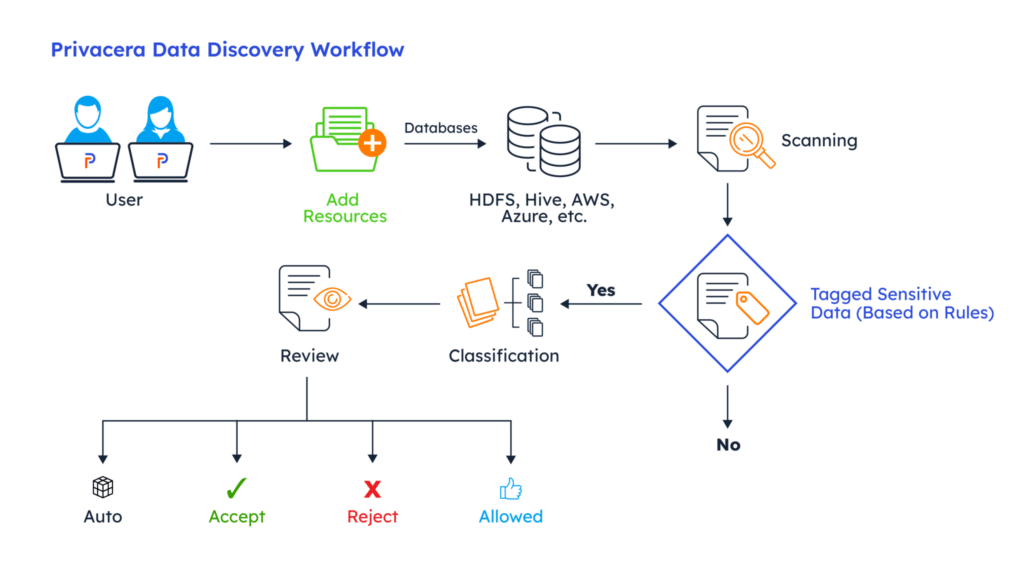
Although thousands of enterprises worldwide have already used Ranger for its robust and extensible data access control framework, the open source community never stops contributing to the project in order to make Ranger a more powerful, compelling enterprise solution. In the recent blog published by Apache Software Foundation, the author discussed the advancement of three different access control approaches employed by Ranger, which are:
With its sophisticated policy model and access control mechanisms managed through a single interface, Apache Ranger effectively addresses policy and access inconsistency across the various Hadoop components. However, the same challenge exists in the cloud but on a far larger scale. Suppose the compute engines of the Hadoop ecosystem are replaced with the various cloud services that are routinely used as part of any company’s public cloud infrastructure today. It becomes clear that the governance and access control issues of the Hadoop data lake are alive and well in the public cloud.
Enterprises demand a single platform to authorize access to disparate cloud services, and Privacera addresses this need by extending Ranger’s enterprise-grade framework to the cloud. Privacera’s unified access governance technology provides single-pane visibility and consistent access management across hybrid- and multi-cloud environments via fine- grained access control, automated sensitive data discovery, dynamic masking and encryption, and continuous audit and monitoring in one scalable platform. Privacera natively integrates with all major cloud vendors and modern data platforms (Databricks, Snowflake, Starburst, Dremio, among others), governing petabytes of enterprise data that helps their customers drive responsible data-powered performance.
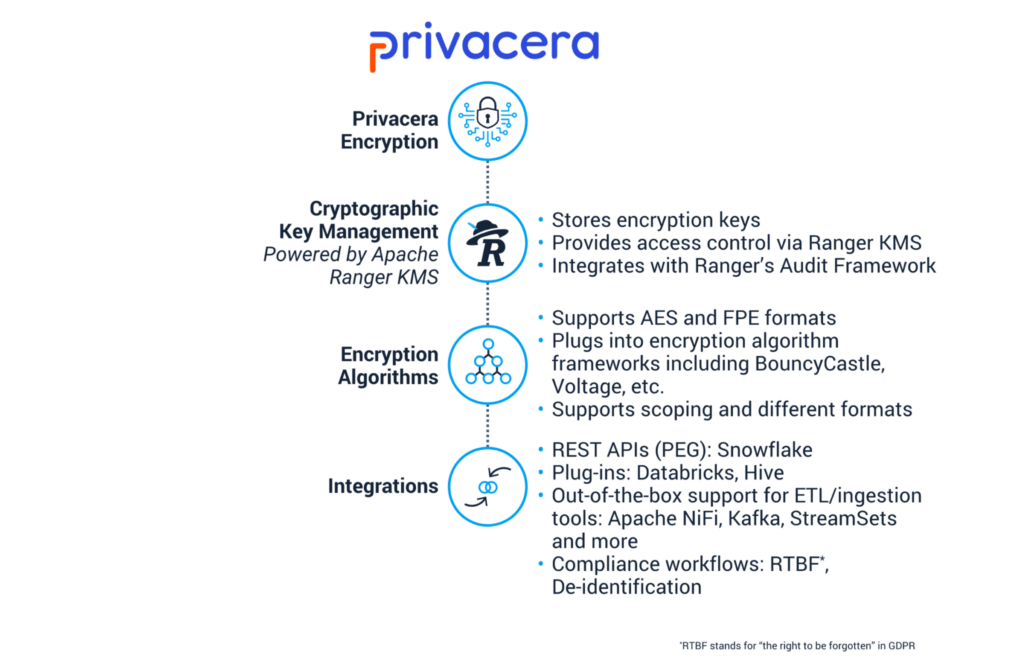
To prepare for the data governance challenges on a larger scale in a more complex cloud landscape, Privacera has enhanced Ranger in three functional areas to support the full lifecycle of cloud data governance:
To learn more about the additional Privacera enhancements and functional capabilities, read our latest white paper for detail.
At Privacera, the migration of on-premises Hadoop data lakes to the cloud is the primary use case among our customers. When companies decide to migrate their analytical workloads to the cloud, they need to migrate data and the usage context to their cloud infrastructure, including access control and data governance policies. Without proper access governance in place, enterprises cannot rapidly democratize data and risk missing critical insights that can add value to their business.
For companies that had invested the effort and resources into building their access control policies in Apache Ranger to govern their on-premises data lakes, they can now instantly extend and reuse the existing Ranger policies in the cloud via Privacera. Organizations can significantly accelerate the process to onboard their users to the subscribed cloud services and help ensure the success of their cloud initiative.
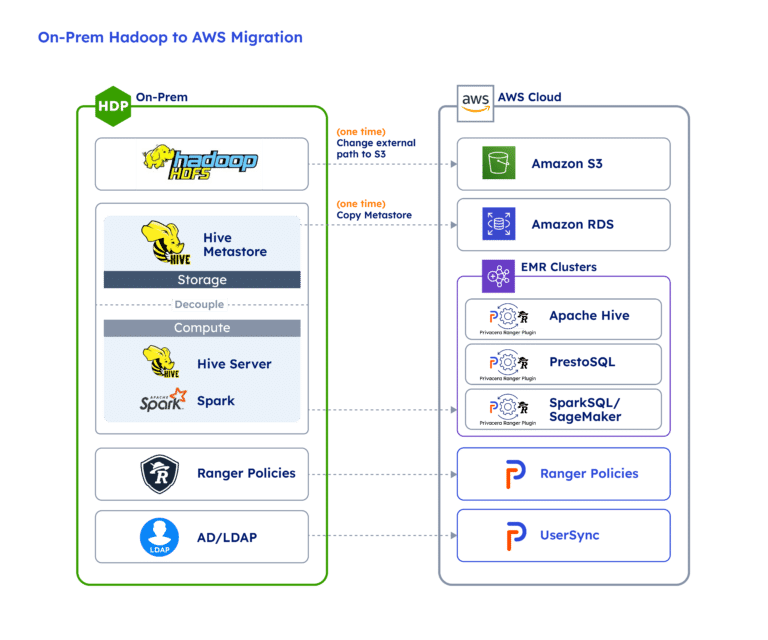
For more information on how Privacera enables a seamless cloud migration leveraging Apache Ranger, attend our upcoming webinar on Thursday, April 21 at 10am PT where Christopher Jackson, Sr. Startup Solutions Architect at AWS and William Brooks, Senior Director Partner Product Management at Privacera will share how enterprises can use Privacera’s Unified Data Access Governance platform to seamlessly migrate their on-premises data security policies to AWS.
Author