



Dec 14, 2020
The Roadmap to a Secure, Modern Data Enterprise: Data Privacy and Governance for Hadoop-to-Cloud Migration
Read More

The term “modern data stack” has received significant attention over the last several years. A search on Google comes back with an astonishing 115 million results. The origin of this term is widely agreed to be found in “Emerging Architectures for Modern Data Infrastructure” by Matt Bornstein, Martin Casado, and Jennifer Li of VC Andreessen Horowitz.
Modernizing the data stack requires special focus on one thing: industrializing data. Given this, CIOs and CDOs who earmark investments in this category should set the goal to create a modular and agile organization where data is a strategic asset. When viewed like this, data becomes foundational to obtaining business outcomes, including:
Realizing these goals means the modern data stack needs to eliminate data silos and proprietary management systems. The biggest challenge for legacy organizations has been, of course, “silos and spaghetti”—a tangled enterprise organizational structure with multiple departments performing similar functions, but failing to work together or share data. A modern data stack addresses this mess, tackling tech debt and data silos, and enabling an advanced data culture.
Aside from variations in execution according to custom enterprise needs, experts widely agree on the modern data stack strategy. Constellation Research’s VP and Principal Analyst Dion Hinchcliffe says, “Data leaders need a way to systematically create and manage a data fabric across all clouds, with local variation only occurring when required.” Former TD Ameritrade Chief Enterprise Architect Craig Milroy agrees and suggests “A modern data stack should result in less data silos, less tech debt, more data exchange (internal/external), self-service data access, and data governance (understood data, including data quality); and exceed business expectations.”
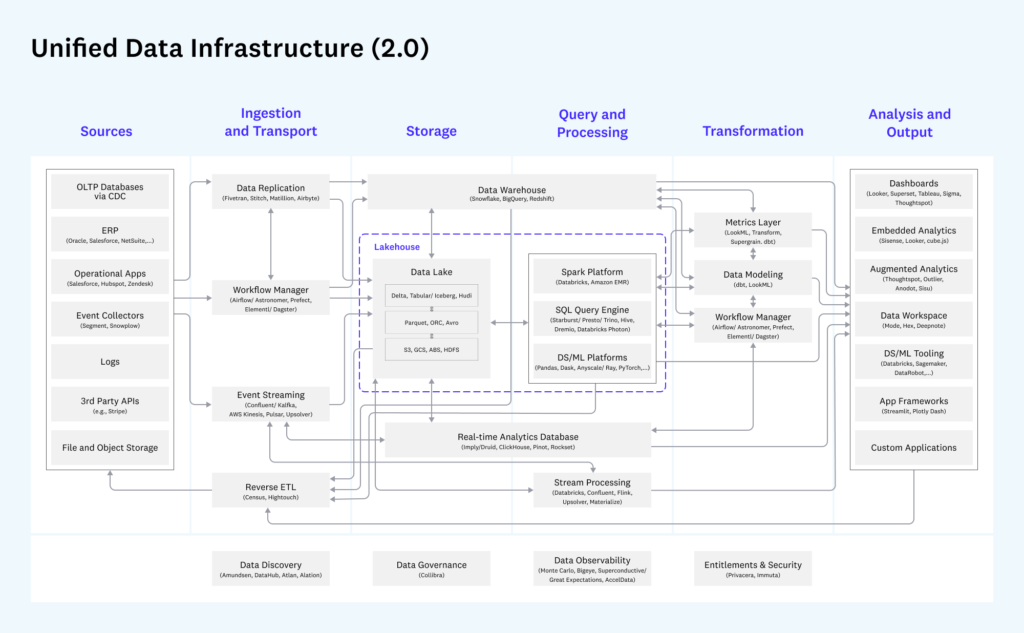
Before we delve into the next section, we should first applaud how the modern data stack considers the importance of data discovery, data governance, data observability, entitlements, and security. The challenge is these functions are neither separate nor provided by one company or a single product. What’s more, many of the companies shown are slowly becoming competitive with each other.
Now, let’s start with data discovery. Essentially, there are actually three types of data discovery:
All three functions are equally important. The first makes data accessible for self-service discovery. The second type facilitates understanding the presence and location of sensitive data needing protection. And the third helps data users, data stewards, and data engineers understand the condition of data, where it came from, and how it has been processed or manufactured.
Data governance is not a standalone strategy. Data governance needs to be practiced for discovery, observability, entitlements, and security. Data catalogs and data observability systems should be governed in terms of how they create access to data and glossaries, including how they create and manage data quality. For this reason, policies are required for making metadata usable as well as for quality and testing. These data governance policies ensure data in a catalog is usable and governed.
Entitlements at their core are about policy and controls. While entitlement and control policies can originate in separate data governance solutions, why should policies be separated from their controls? This is a critical matter for compliance auditing.
We suggest two new and important roles for entitlements and security:
And finally, we call attention to a missing component we refer to as “manage and measure.” From end to end, how are we managing the process of data? In the assessment process, this should be improving over time. Therefore, we suggest a data-process-analysis block be added at the bottom of the above “Emerging Architectures for Modern Data Infrastructure” diagram. This should embody modern notions like DevOps, DataOps, and DataGovOps.
The value and benefits of a modern data stack are undeniable. However, it needs to be reframed to determine what goes where and why. Clearly, the functions are correct. But they will, in fact, be partitioned between multiple applications. And finally, a measure-and-manage function needs to be added, so data processes will improve over time. Data needs to be managed, assessed, and improved continuously. Otherwise, it will not be modern for very long.
For more ideas on reshaping your current data stack and building and maturing to a modern data stack, read our whitepaper: Rethinking the Modern Data Stack for the Age of Gen AI.
Author