




Aug 28, 2024
Activating Data Security Posture Management
Read More

Building a secure foundation for GenAI excellence
The world is buzzing with generativeAI (GenAI) pitches and promises. In fact 94% of business executives surveyed by Deloitte indicate they believed GenAI to be critical to their own organization’s success. But there are dark clouds surrounding this desire. According to multiple organization’s research, 55% of organizations are concerned about data management and governance. Even Salesforce has found in its own research of 150 CIOs from companies with 1,000 or more employees, the slow pace of implementing enterprise-wide AI strategies is largely due to the preparatory work CIOs believe they must prioritize first. While there is enthusiasm for AI’s potential, CIOs face significant hurdles, with security concerns and data quality issues topping the list. Security or privacy threats and a lack of trusted data rank as their biggest fears.
At the same time, Gartner suggests that by 2025 30% of GenAI projects will be abandoned after the POC (proof of concept) stage and that 3 of the top four issues relate to security, risk, and governance. And the sobering thought (drum roll please) – these projects on average are believed to cost between $5m and $20m in upfront costs.At the same time, Gartner suggests that by 2025 30% of GenAI projects will be abandoned after the POC (proof of concept) stage and that 3 of the top four issues relate to security, risk, and governance. And the sobering thought (drum roll please) – these projects on average are believed to cost between $5m and $20m in upfront costs.
The title was born during a series of conversations I had with a good friend and advisor. For context, these took place during the Olympics in Paris this year. The question we raised was WHO WANTS TO BE AVERAGE? In anything? No one sets out to be average. Everyone wants to be a winner, and when the stakes are as high as they are in GenAI then so much more – why on earth would you want to be average?
As an athlete, you know what it takes to be a winner or a leader. It takes planning and a long term commitment to excellence over a long period of time if you want to go to the olympics.
My belief is that we can draw parallels between building a winning mindset for sports and building a foundation for excellence in your business – in this case for your GenAI initiatives.
BCG did a survey recently on the state of GenAI adoption and they found that around 10% of respondent organizations are what they classified as SCALING. i.e. they are getting real value and are scaling their GenAI initiatives. I would call these our LEADERS. According to the survey 50% are in the middle – PILOTING GenAI in some fashion. Maybe these are our AVERAGE ones.
What is really interesting is that 5 distinct capabilities come to the front where the SCALING organizations excel!, Privacera’s platform offers a comprehensive solution that balances security with business agility.
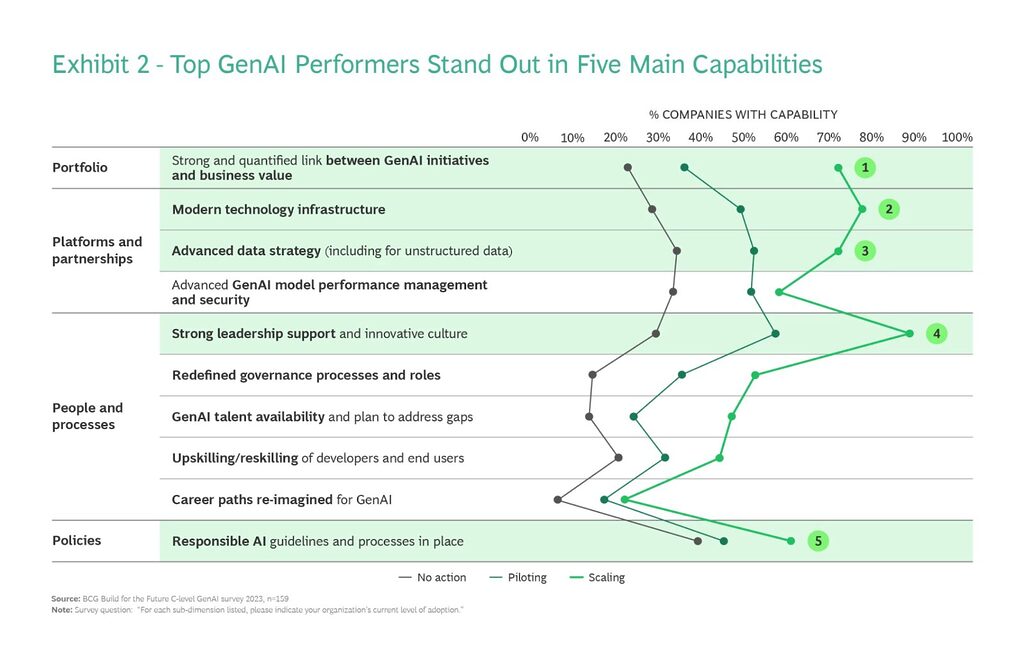
Focusing on the green rows, these are focused on:
The LEADERSHIP BUY-IN and tying the initiative to business outcomes seem very obvious and most of us know that failing to deliver business value will kill any technology (and other) initiative.
I will focus the rest of this blog on the remaining three that I believe are crucial building blocks for a secure foundation – one that will set you up for repeatable excellence and scaling.
I will combine the aspects of technology and data modernization into one group since I don’t believe it makes sense to separate them. Andreessen Horowitz introduced this reference architecture for the modern data and technology stack some years ago. It provides a very comprehensive view of all the distinct services and flows that exist across the entire data value chain. One interesting observation is that they highlight a series of services at the bottom of their diagram that are transversal to the rest – i.e. these are services to consider holistically and not to be implemented as silos in each service or flow. These services include Data Discovery, Data Governance, Observability, Entitlements and Security.
I propose this framework is a power starting point as you consider modernizing you technology infrastructure in support of GenAI.
We have taken a little liberty by expanding the original to include the aspects of GenAI in this model below.
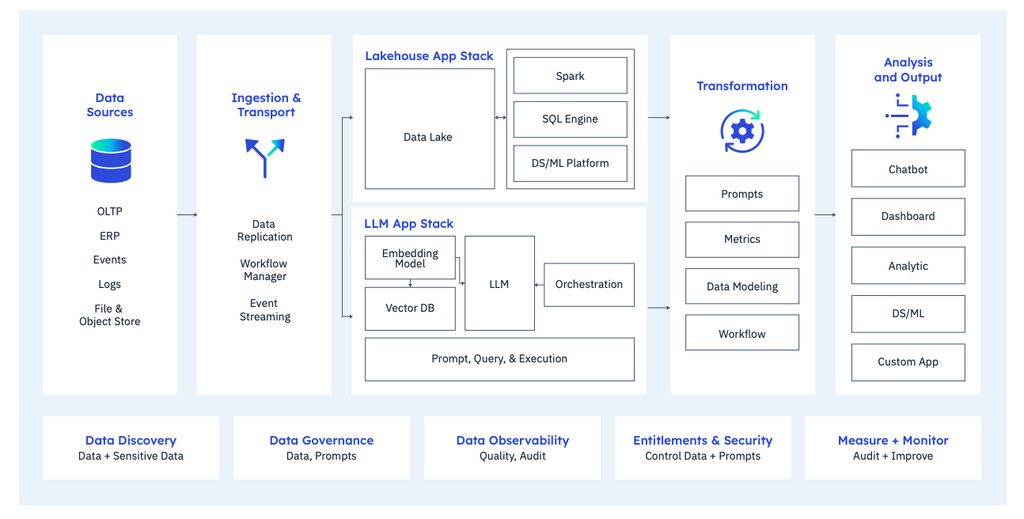
You can read a more detailed explanation of the thinking in this whitepaper Rethinking the Modern Data Stack For The Age Of GenAI. The key aspects from this in my view:
Building a foundation for secure and responsible GenAI has two levels. (1) Your organization’s policies and guidelines as it relates to the use of GenAI and (2) the implementation of those policies and guidelines as systematic and automated controls across your technology and data stack. For the first, you probably have this in place or are in the process of putting that in place. The second is a little harder and requires a deeper understanding of the inner workings of GenAI.
At its most basic level, the GenAI application (like a chatbot you might build to support your customer support agents) will consist of the model (eg. OpenAI), some application that is orchestrated through the use of some libraries like Langchain. And then there is the part where you store your own company relevant data – usually in some vector database. The flow is pretty straight forward:
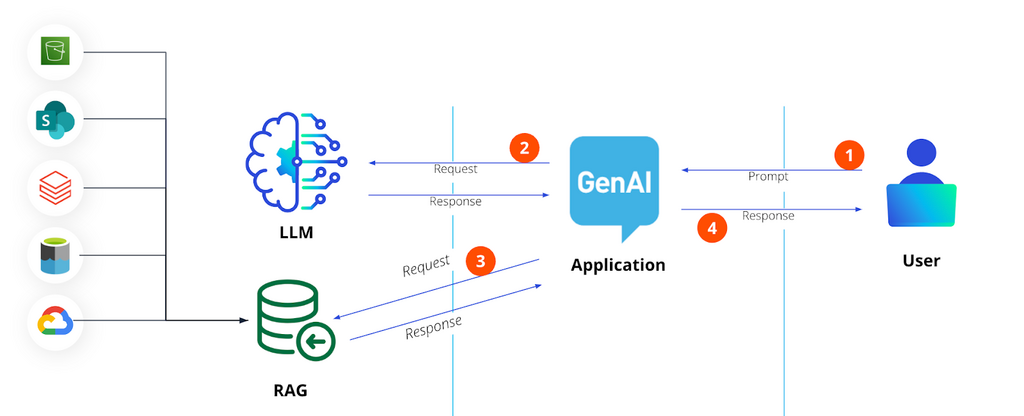
At every interaction there are risks for security and safety issues arising.
To further exacerbate the problem, most applications now will contain multiple models and multiple agents or RAG processes.
Based on the conversations we have had with nearly a 100 organizations over the past 12 months, a couple of things are apparent.
The problem with that is the use case grows and now sensitive or restricted company data gets included. And then they find the possible questions are not simple one liners like “Wis Equinox Technologies a customer”, but rather “Does our ABC product support access to Amazon EMR and when will we provide support for EMR Serverless?” When this happens the project grinds to a halt. And the project team is suddenly trying to invent governance and security that go far beyond the realm of the embedded guardrails.
Privacera AI Governance (PAIG) is a comprehensive GenAI security, safety and observability solution that works independently from your models or RAG technology choices. PAIG is designed on an open and extensible framework to be orchestrated into your application to provide policy-based controls to secure access to sensitive information that might be in your models or RAG systems. PAIG manages all aspects of data security and safety across the entire lifecycle, including:
The potential business value and impact of GenAI is undeniable and perhaps existential for your organization. If you are in the process of piloting or perhaps already have an application in production, you can set yourself on a path for repeatable excellence today. Don’t delay your thinking about security, governance and responsible AI.
For a deeper dive, watch our webinar “How Not To Be Averand in GenAI”. If you want to get your hands on PAIG, you can try the open source version at www.paig.ai. Alternative, if you are interested in learning more about Privacera, reach out to our team and schedule a demo or conversation.
