



Jun 10, 2021
Privacera + Databricks Unity Catalog: A Secure Combination for Open Data Sharing
Read More

Databricks Unity Catalog is a powerful governance solution for all AI and data assets, including files, tables, and machine learning models in your Databricks lakehouse on any cloud. With Databricks Unity Catalog access control, users can now easily access the same database and table from any workspace by using both Database SQL Endpoints and Databricks Spark Clusters. Unity Catalog access control features also provide rich APIs to fortify and automate access policy management.
Databricks’ centralized platform for coding controls offers significant benefits, but challenges arise when it comes to medium-to-large enterprises with extensive and diverse databases and datasets requiring consistent protection. Examples of such challenges include:
This is where the combination of Databricks and Privacera becomes particularly advantageous, offering a comprehensive solution that benefits both enterprises and medium-sized companies by addressing these critical issues effectively.
Business teams need to make timely and confident decisions when sharing data. Privacera’s Governed Data Stewardship (GDS) brings a paradigm shift in how data access management and compliance is implemented to support timely and confident sharing, allowing access to be managed at the dataset rather than the individual resource level (e.g. tables and columns). A dataset is essentially a logical, abstracted view of the data—for instance, marketing data—that could comprise several and diverse physical databases or files. This allows grouping of various resources under a single dataset for simplified policy creation and application giving Data Stewards and Data Owners the ability to provide Data Analysts, Data Scientists, and other users discrete access. This simplified access workflow policy management helps ease governance from a central UI access point for users and groups across platforms and data silos, providing significantly faster user onboarding and application of policies to new data.
Behind the scenes, GDS automates the entire process by breaking down rules at the data level into tag-based policies, attribute-based policies, and resource-based policies to enforce complex compliance requirements. These database-specific rules are then automatically inserted into each data source for native enforcement. An example of this would be restricting access to data records in tables and masking/de-identifying sensitive or personal identifiable information (PII) fields that users do not have the privilege to view. In addition to building policies, Privacera keeps track of who has made changes to them and users who have accessed the data, delivering instant audit reports to meet compliance and security requirements.
Privacera is designed to work as an intuitive user interface to manage access. The platform also provides a rich API based on the power of open-source Apache Ranger to codify the management of access policies. Thousands of customers have used Apache Ranger’s REST APIs to manage access policies through automation using YAML, Git, and other tools to implement a robust and highly scalable PolicyOps solution. For many large organizations, compliance demands they tighten controls, but this can also decelerate access. Privacera creates smart access using several technologies, which balances controls and access. This speeds up access for people who have the right to process information.
Privacera supports dozens of integrations with a broad range of structured and unstructured data sources with our open-standards-based platform. As one of the first Databricks partner integrations, Privacera comprehensively integrates with Unity Catalog, translating key high-level access policies into complex Unity Catalog constructs. This reduces the complexity of managing these constructs and eases the implementation of access governance as you apply these policies across your data sources. Privacera supports the following via the Unity Catalog integration:
Due to compliance reasons, your data analysts may not have the privilege to view a customer’s email address regardless of which table or column contains it. This use case can be implemented using the combination of Unity Catalog and Privacera.
In this case, we are defining the policies in the Privacera UI and running the query using DatabricksSQL Endpoint.
In this case, there is a global sales table with sales data from across the world. Data Analysts are only supposed to see data from the country they belong to. This policy can be applied more appropriately by using attribute-based access controls. Privacera extends Unity Catalog to enforce this policy by following these steps:
In this case, we are defining the policies in Ranger YAML format, which will be used by Privacera’s PolicyOps to automate the management of the policies.
Using Privacera, you can simplify and automate the management of policies with Unity Catalog access control while meeting complex Security and Governance requirements across your entire data landscape. Streamline compliance and accelerate data sharing to better enable data science projects with Databricks + Privacera.
Unity Catalog will be releasing more extensive capabilities. As these features are made generally available to organizations, Privacera will further simplify the management of these policies by translating the enterprise’s global policies into Unity Catalog native enforcement layer.
Privacera is integrated with the Data Security category of Partner Connect and is available today with a free trial license. Set-up is quick and easy as the Privacera-Databricks environment is pre-configured and ready to go with a pre-canned dataset and access policies, Unity Catalog integration and quick-start tutorial.
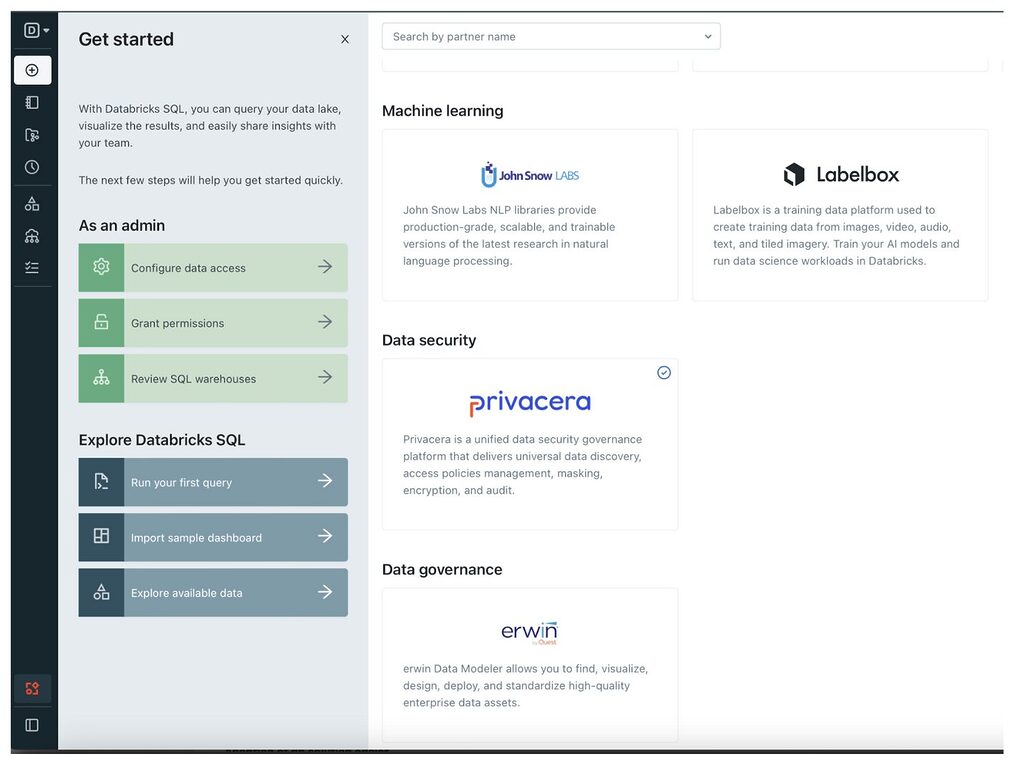
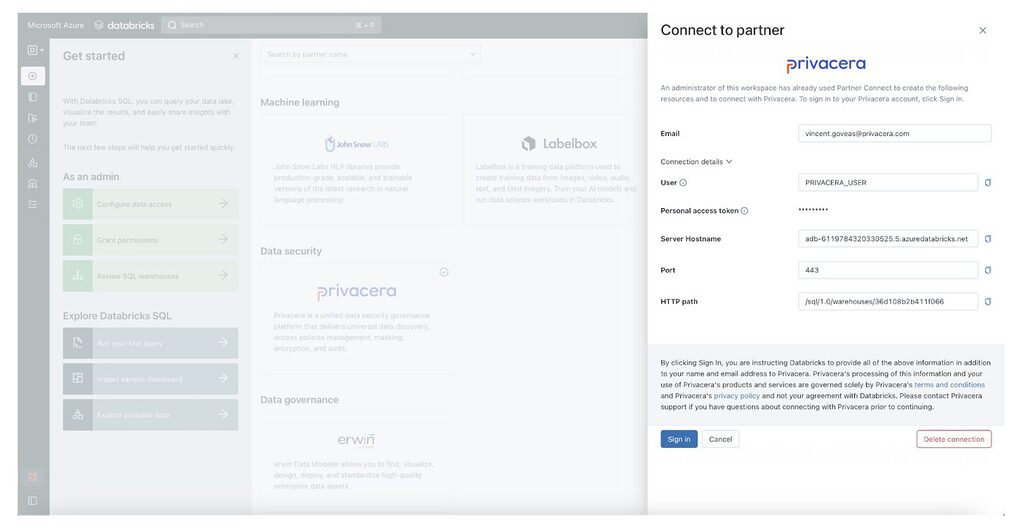

Databricks: Connect to Privacera using Partner Connect
Privacera: Databricks Partner Connect – Quickstart for Unity Catalog
Want to learn more? Schedule a demo with us to see Unity Catalog and Privacera in action.
Author