



Dec 14, 2020
The Roadmap to a Secure, Modern Data Enterprise: Data Privacy and Governance for Hadoop-to-Cloud Migration
Read More

Amazon EMR is one of the most popular cloud data analytics services for Hadoop and Spark-based workloads. It provides the flexibility and scalability to effectively address the changing needs of enterprises today. For short-term or immediate tasks, EMR users can create an ephemeral Hadoop cluster on-demand, scale the cluster up or down as computing needs change to control costs, and terminate it when tasks are completed. The ability to run multiple instances enables each line of business to manage their own clusters for specific needs, complete jobs faster, and control charge backs. These benefits account for EMR driving the digital transformation for countless organizations’ migration from on-premises Hadoop to Amazon EMR.
One of the recommended approaches for a successful and seamless on-prem Hadoop to AWS migration–without interrupting current use cases–is to leverage the existing model of data governance, security, data analysis, and data exploration as implemented in Hadoop distributions such as Hortonworks/Cloudera Data Platforms. At the same time, the designated cluster needs to be secure, auditable, and compatible with existing users and groups in Active Directory. To further simplify authorization, SQL policies from Apache Ranger could be migrated to EMR services like Apache Hive, Apache Spark and Trino/PrestoSQL. This enables end users such as data scientists, data analysts, developers, and power users to seamlessly transition to cloud data analytics by using tool sets like Spark, Hive, and Ranger on Amazon EMR.
Recently, Sun Life, a leading Canadian financial services company, was able to successfully migrate their data from on-prem Hadoop to AWS with the help of Privacera. Sun Life’s existing analytics processes were based on a Hadoop system which was at over 80% capacity with little room left for future expansion. The enterprise needed to quickly scale out its multi-user analytics infrastructure from on-prem Hadoop to a AWS cloud-native analytics data platform. This involved migrating terabytes of data along with cumbersome analytical processes to the cloud, while ensuring scalability, performance, regulatory compliance, and cost-efficiency associated with data storage and third party support. Powered by Apache Ranger, Privacera’s unified data access governance platform offered Sun Life a seamless path to leverage its existing Apache Ranger investment and securely migrate its data without exposing sensitive elements, while implementing consistent, fine-grained access controls. This enabled Sun Life to achieve its dual objectives of meeting the company’s cloud-based analytics initiatives in accordance with robust data security standards. In general, its migration from Hadoop to Amazon EMR took places in 4 key areas:
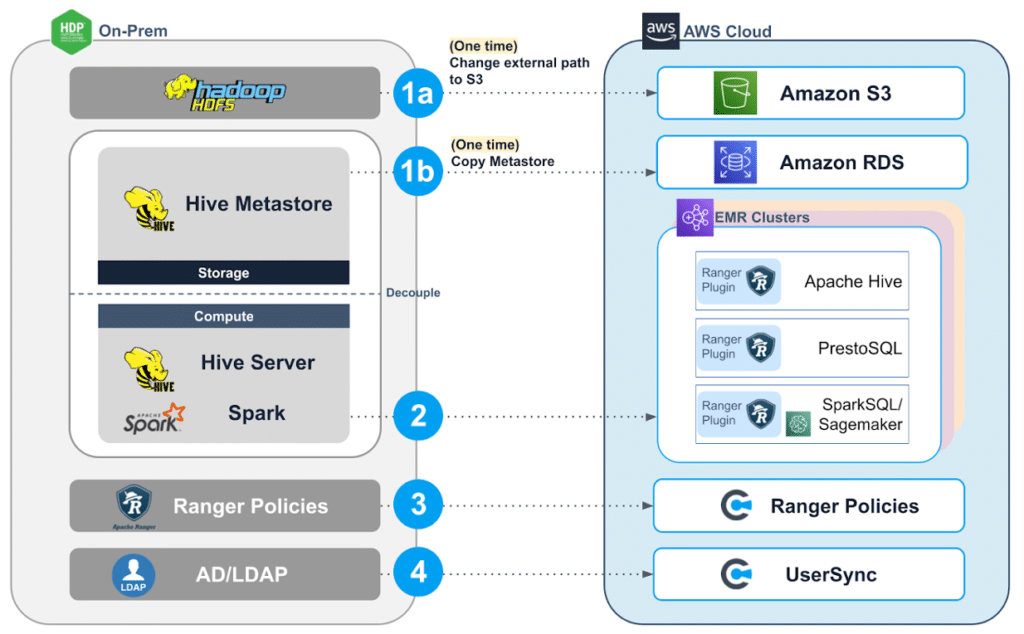
First area of focus was to decouple storage from compute to scale the analytical jobs independently of storage.
Sun Life’s storage had two subcomponents that needed to be migrated: HDFS file system and Hive Metastore
HDFS File Systems
All HDFS file systems were migrated to S3 to reduce TCO.
Hive Metastore
There are two options for Metastore in the AWS Cloud. The preferred option is to use AWS Glue. The other option is to set up an external Hive Metastore in Amazon RDS. Using Glue or external Hive Metastore enables multiple ephemeral EMR clusters to talk to a central Metastore for table definition and storage location. Moving Hive MetaStore from on-premises is one of the critical steps for the migration of the workloads to EMR.
There are three main steps in migrating Metastore:
Step 1: Export Hive Metastore from on-premises
Step 2: Update the storage locations for the tables and import them in the new Metastore/AWS Glue
Step 3: Configure the hive-site.xml file to point to the new Metastore/Glue in AWS
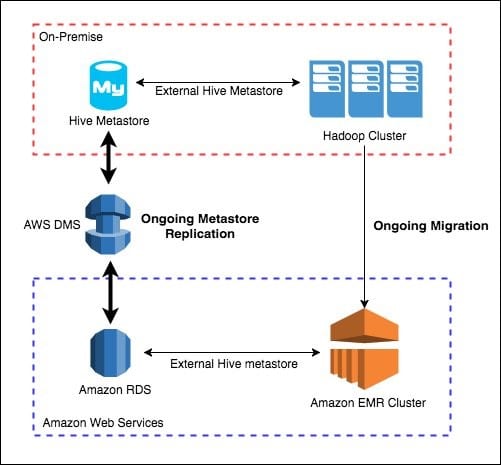
Depending on a company’s migration plan or requirements, Metastore can be migrated in one of two ways:
Sun Life chose a one-and-done migration option that allowed the company to shift their workspace entirely and never worry about migrating again. This approach was perfect as Sun Life planned to run their existing Hive workloads on EMR. The diagram on the right illustrates this scenario.
Glue is another alternative for Hive Metastore. Glue provides a lot of additional capabilities and support within the AWS ecosystem, like accessing the same database and tables using Athena.
As part of the migration, Sun Life also needed to move all their analytical workloads from Spark and Hive from on-prem Hadoop to EMR. Therefore, they leveraged Apache Spark for analytics workloads while using Apache Hive and PrestoDB/PrestoSQL for interactive ad-hoc queries. This enabled Sun Life to differentiate their workloads by creating ephemeral EMR clusters on-demand, scale the clusters up or down as computing needs change to control costs, and terminate them when tasks are completed. Across the various EMR clusters performing different jobs, Privacera enabled centralized access control, auditing, and security to ensure consistent data governance.
Since its inception Privacera has adopted the open standard policies from Apache Ranger. At Sun Life, tools based on Ranger REST API were used to seamlessly migrate fine-grained access control policies to Privacera on AWS. Sun Life did not use tags to classify sensitive information, but if tags were involved, they would also be migrated. An automation of this migration will ensure classification of the data in the new storage system as well. With Privacera, data policy migration essentially becomes a lift-and-shift effort for enterprises while maintaining existing compliance policies.
Sun Life’s integrated Active Directory with Amazon EMR and Privacera enabled authentication on EMR clusters. As part of the migration, Active Directory was integrated with Privacera’s UserSync service for applying the users/groups/roles based policies in the EMR clusters. Sun Life also used it’s corporate single sign-on (SSO) to gain access to Zeppelin for running SQL queries. This ensured a familiar user experience in the new environment.
Soon after starting the migration process, Sun Life was able to use Privacera for data management, access control, and compliance across 200 Amazon EMR nodes. Sun Life can now get data into the cloud data lake as quickly as possible and then apply access rules so analysts and business users can use the data to generate insights to effectively drive the business. Privacera optimized the time-to-value of data for Sun Life as access requests that used to take three to four weeks to program can now be reacted to in less than two days.
Today Sun Life is applying the integrated capabilities of Apache Ranger, Privacera and AWS in areas ranging from service desk call recordings to breach vulnerabilities to improve its competitive position and place it as a leader in its industry.
Learn more about Privacera here, or contact us to schedule a call to discuss how we can help your organization meet its dual mandate of balancing data democratization with security to maximize business insights while ensuring privacy and compliance.
Author