




Aug 28, 2024
Activating Data Security Posture Management
Read More

Introduction
In today’s data-driven world, organizations are increasingly reliant on data to fuel decision-making, innovation, and competitive advantage. However, with vast amounts of data comes an inherent challenge: ensuring that it is both easily accessible and securely governed. In this landscape, data catalogs and data security governance play pivotal roles in facilitating seamless, secure, and auditable data access. By unifying these two capabilities, organizations can streamline access, enhance compliance, and improve security without sacrificing efficiency or agility.
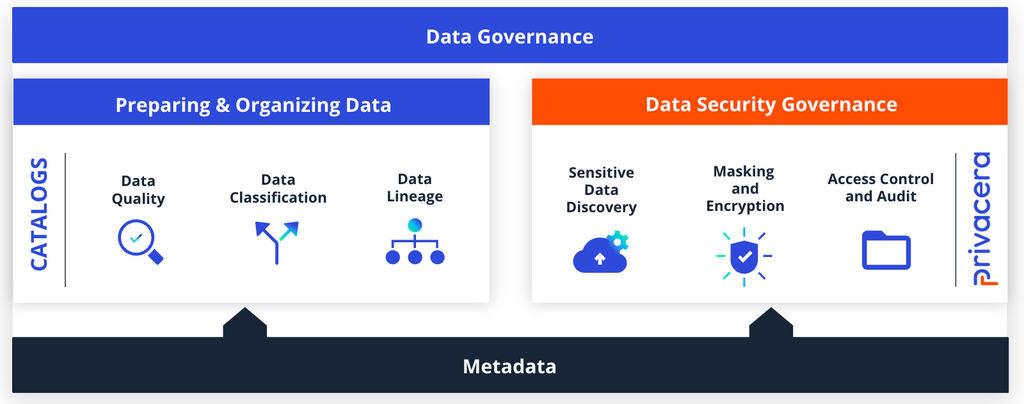
Comprehensive data governance
A data catalog serves as the central repository where metadata about an organization’s data assets is stored and organized. It is a comprehensive inventory of all the data available in an organization, along with its definitions, relationships, and attributes. In the context of a larger data ecosystem, data catalogs are critical in making data discoverable and manageable for all users. In addition to technical metadata, data catalogs often also contain elements to make it easier for data users to understand and interact with the data. For instance business glossaries provide business friendly descriptions of technical metadata to help the data consumers.
Another aspect of making data usable and understandable is the policy associated with it describing how data can or should be used. For instance, a policy pertaining to GDPR could describe how customer data might be used and can be added to the catalog. The data catalogs are a perfect location for capturing these written policies because they can act as the centralized source of truth for data management. These policies dictate how data should be handled, stored, accessed, and shared across various departments. By centralizing these policies in the catalog, organizations ensure consistency, clarity, and transparency when it comes to how their data should be governed.
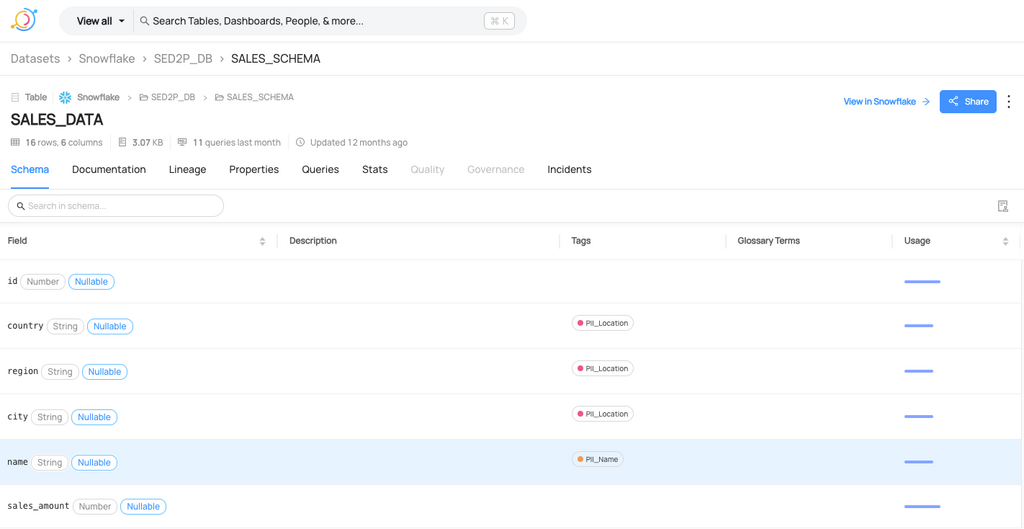
Typical data catalog view with metadata
Data catalogs are an integral part of a comprehensive data governance solution because they enable efficient management of data assets while ensuring compliance – leveraging data security and access governance tools – with internal and external data governance policies. They provide visibility, accountability, and transparency into data access and usage, making it easier to apply governance frameworks, enforce security policies, and maintain compliance across a large organization.
While data catalogs focus on organizing and making data discoverable, data security governance ensures that the right people have access to the right data at the right time, and that sensitive data is protected from unauthorized access or misuse.
Data security and access governance refers to the policies, practices, and tools used to control access to and protect data. I.e. where the data catalog contains a documented version of a policy, data security governance is about enforcing the controls and rules relating to the policy. It is designed to ensure that only authorized users or systems can access sensitive data while enforcing regulatory compliance requirements. This involves establishing clear access controls, monitoring data activity, and implementing data masking, encryption, and auditing.
Data security governance is powered by the metadata and information captured in data catalogs, which can include:
A robust data catalog captures crucial information necessary for data security and access governance including:
Data scanning and classification aids in identifying and managing sensitive data that might be present in your data, ensuring compliance with data protection regulations (e.g., GDPR, HIPAA). The data scanning and classification component of data security governance involves scanning data repositories to identify sensitive data (such as PII or PHI) and classifying and tagging it accordingly. This process helps organizations automatically apply the appropriate governance policies to sensitive data, ensuring it’s properly secured.
For organizations to efficiently govern data access, data catalogs and data security governance systems must share data with one another. By doing so, data security governance solutions can leverage the data catalog’s metadata (including classifications and lineage) to apply access policies and protections automatically.
For instance, if data is classified as restricted in a data catalog, the data security governance system can use that information to implement access restrictions, encryption, or masking, ensuring that only authorized users can access sensitive information. Similarly, data security and access governance solutions should share information relating to audits and user activity back into the data catalog to enable comprehensive auditing of who accessed which data, when, and why.
Compliance and privacy auditors require complete visibility into an organization’s data usage and access patterns. By connecting data catalogs with data access governance systems, auditors can:
A unified approach to data cataloging and data security governance provides auditors with a single source of truth, making the audit process more streamlined, transparent, and accurate.
Many organizations approach data access and security by simply using the native controls provided by a database or cloud platform. The challenge these organizations then face is that this leads to inefficiencies, compliance risks, and security gaps. Some of the key problems with siloed data access and security governance solutions include:
To address these challenges, integrating Privacera with your data catalog, such as DataHub, creates a unified solution that streamlines data access, security governance, and auditing. Here’s how the solution works:

Architectural view of data catalog and data security and access governance integration
In an era of increasing data complexity and regulatory scrutiny, unifying data catalogs and data security governance is necessary. By integrating these capabilities, organizations can streamline data access, ensure robust security, and maintain auditability without sacrificing efficiency. Solutions like Privacera, when combined with a data catalog, create a seamless flow of data governance and security, making it easier to manage sensitive data while staying compliant and secure. With the right approach, organizations can unlock the full potential of their data while minimizing risk and maximizing trust.
To get a firsthand view of Privacera, please schedule a demo and conversation with a solution architect.
