




Aug 28, 2024
Activating Data Security Posture Management
Read More

Transforming Data Governance: Automating Access & Control
In today’s fast-paced, data-driven world, organizations face a dual challenge: they must maintain robust governance frameworks while ensuring agile access to critical information. Traditionally, organizations have resorted to adding approval layers before a new data is introduced to the system. This requires manual interventions, and slows down innovation and delays data-driven insights.
In this article, we will explore how rethinking our approach to data governance and leveraging automation can empower organizations and its users to achieve “Birthright Access” to data. This model ensures that every new dataset is immediately and securely available to those who need it, without compromising on security or compliance.
As organizations dive into specific news and use cases, they realize that one-size-fits-all solution is not scalable. In order to streamline data operations, they have to address challenges like multi-cloud integration, environment diversity, and process efficiency. In our discussions with data leaders from various industries, we realized that most, if not all, have the challenge of granting immediate access to newly created dataset in a secure way. Let’s look into an example of adding a new dataset.
Consider a large company, where it is typical that new datasets are introduced multiple times a day:
In traditional data governance models, administrators must navigate a series of manual steps to ensure proper access controls. Managing new datasets follows a sequential workflow. At a high level, this involves the following phases:
1. Data Ownership and Ticketing: The process begins with the data owner submitting a ticket that routes through IT administrators and compliance officers.
2. Policy Creation: Compliance teams assess the dataset—reviewing elements such as personally identifiable information—and draft new policies as needed.
3. Manual Intervention: Finally, an administrator verifies and makes the data public.
Here is an illustration of how this actually takes place:
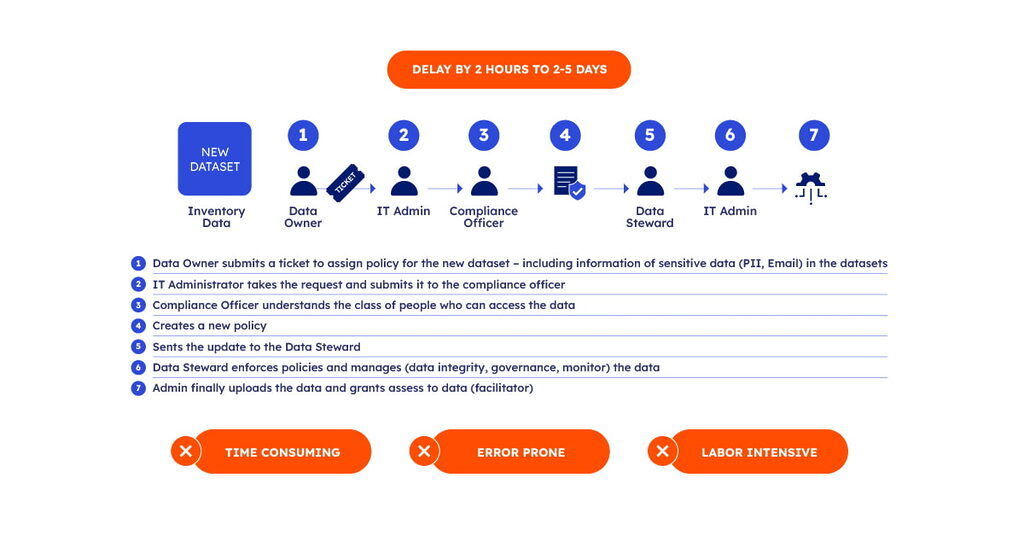
While thorough, this sequential process is both labor intensive and prone to delays and errors. Moreover, the repetitive creation of similar policies for new datasets can compound inefficiencies.
To overcome these challenges, modern data governance is shifting towards automation through Privacera. Based on your environment and need, there are three key approaches:
1. Owner-Driven Tagging
2. Automated Discovery and Classification
3. Leveraging Existing Data Catalog for Discovery
When a new dataset is created, the data owner first assigns a specific tag in Privacera that defines its sensitivity level and access requirements based on predefined criteria (e.g., identifying sensitive columns). Once tagged, the administrator makes the dataset available in the system, allowing public access without requiring additional manual reviews.
Privacera then automatically enforces pre-defined policies, such as masking sensitive information for non-HR and non-US members, ensuring that appropriate permissions are applied seamlessly.
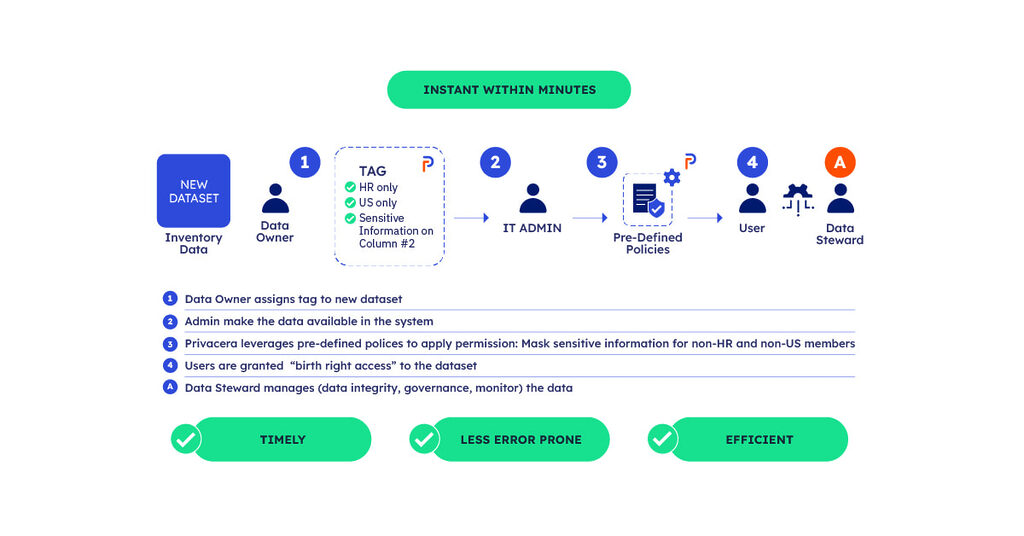
This process enables users to gain “Birthright Access” to the dataset, enabling them to immediately benefit from the data while maintaining robust security measures. Most large organizations will have a dedicated data steward overseeing the entire lifecycle to ensure data integrity, governance, and ongoing monitoring.
Manual tagging and policy application ensures that new datasets are provisioned within minutes, making the process both timely and efficient.
By integrating Privacera, organizations can leverage its automated discovery functionality, which can detect new datasets as soon as they are created. Privacera will analyze metadata – such as schema details and data formats – and automatically assign the appropriate classifications. Privacera then leverages pre-defined policies – such as masking sensitive information for non-HR and non-US members – to automatically apply the appropriate permissions – giving “Birthright Access” to the users right away.
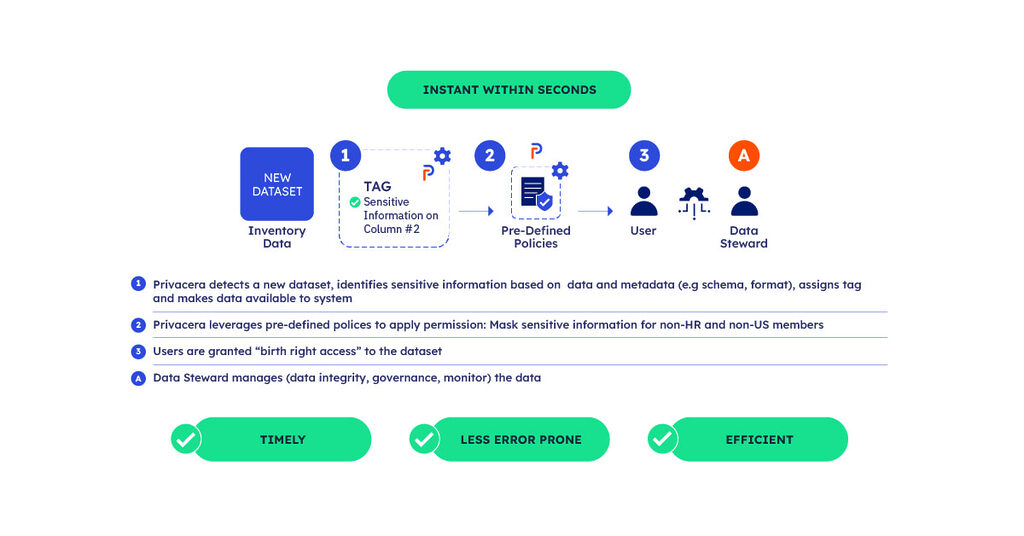
In the instance, organizations eliminate the need for constant manual tagging, ensuring that governance policies are applied almost instantaneously (within seconds) after a new dataset is added to the system.
In environments where robust data catalogs are already in place, new datasets benefit from preexisting governance frameworks. Since the catalog has a repository of standardized policies and metadata, any new addition can be swiftly integrated with Privacera with minimal overhead. This is because Privacera performs a “tag sync” with the data catalog to read metadata. Privacera then leverages pre-defined policies – such as masking sensitive information for non-HR and non-US members – to automatically apply the appropriate permissions – giving “Birthright Access” to the users right away.
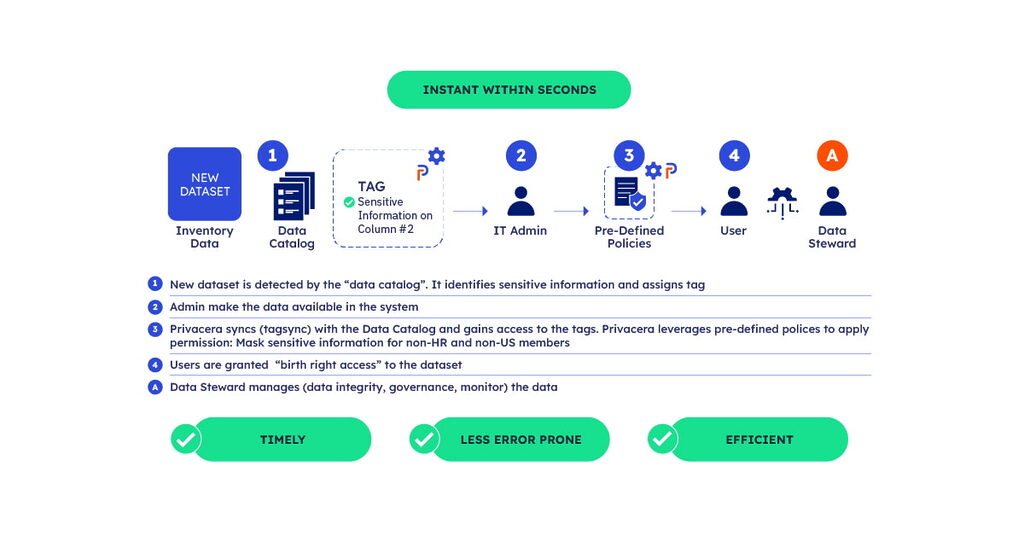
This automation ensures that as soon as data is ingested, it’s already classified and ready for governance actions. The result is a seamless, efficient process that upholds security while expediting access.
NOTE: In some large-scale implementations, where they have a catalog data from S3 alongside lake formation polices, could require multi-step processes. This totally underscores the value to total streaming data.
At the heart of these improvements is the concept of “birthright access.” With policies predefined and automation handling routine tasks, every new dataset is automatically endowed with access rights that align with its classification. This approach means that users no longer face lengthy approval processes when new data is ingested; instead, they gain immediate, governed access that empowers them to act on insights without delay.
Privacera’s fine-grained access control enables administrators to set precise, attribute-based permissions down to the column or cell level. It dynamically applies policies based on data tags, user attributes, and group affiliations, ensuring that sensitive information is masked or restricted as needed. This granular approach minimizes over-permissioning and enhances data security while ensuring that users access only the data pertinent to their roles.

Rather than crafting lengthy, complex policies, Privacera leverages a combination of tags and attributes to create a dynamic “matrix” for policy enforcement. This enables selective masking. For instance, a policy can mask sensitive data such as Social Security numbers—displaying only the last four digits or completely hiding the column from unauthorized users.
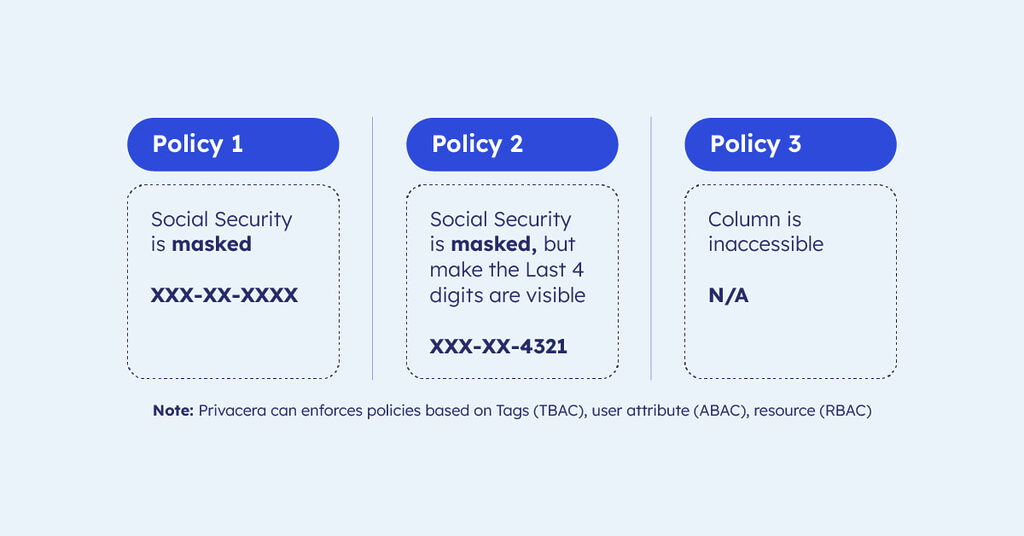
Traditional systems can struggle with overly detailed policies due to character limitations . By applying policies based on predefined tags, even the most specific access requirements are enforced efficiently without computational strain.
The transformation of data governance from a cumbersome, manual process into a dynamic, automated system is well underway. By rethinking traditional models and embracing automation with Privacera, you can (owner-driven tagging, automated discovery, and integration with existing data catalogs) achieve immediate, birthright access to new data. Privacera not only streamlines operational efficiency but also enhances security and compliance. As we continue to evolve our systems, the focus remains on balancing robust control with agile, real-time access—driving greater innovation and competitive advantage in the data-driven era.
To see how Privacera can support your organization, request a free demo today or download our whitepaper “The Blueprint For a Data Governance Program” to learn more about the importance of data governance
